河套 IT TALK 95:(原创)GPT技术揭秘:大模型训练会导向灭霸的响指吗?


1. 大模型训练的套路

昨天写了一篇关于生成式模型的训练之道,觉得很多话还没有说完,一些关键点还没有点透,决定在上文的基础上,再深入探讨一下大模型训练这个话题。
任何一个大模型的训练,万变不离其宗,一定要经历以下几个步骤:
- 模型选择(Model Selection):选择适合任务和数据的模型结构和类型。
- 数据收集和准备(Data Collection and Preparation):收集并准备用于训练和评估的数据集,确保其适用于所选模型。
- 无监督预训练(Pretraining):使用大规模未标记的数据进行预训练,使模型学习通用的语言表示。
- 验证和测试(Verification and testing):评估预训练或者微调后模型在特定任务上的性能,并进总的来说,这些步骤不是简单的线性顺序,具体大家看图来体会。而是在预训练和微调或调优阶段后的验证和测试,都要跟随一个决策是否要调整模型,是否要继续进行微调或调优。根据决策来判定是否选择迭代的循环,通过不断的反馈和优化,逐步提升模型的性能和泛化能力,知道涌现出来的能力,让训练者满意结束训练过程。但让这个过程有个确定起点的话,一定要从模型选择开始。行必要的调整和改进。
- 微调或调优(Fine-tuning):使用标记的任务特定数据对预训练模型进行微调,以提高其在特定任务上的性能。
- 决策(Decision Making):根据验证和测试结果,判断是否需要重新选择模型、调整超参数、重新收集数据等,进一步优化模型。
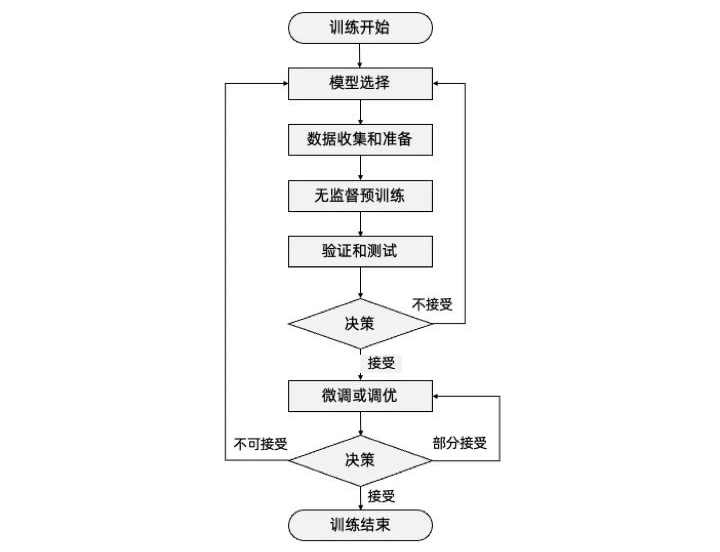
总的来说,这些步骤不是简单的线性顺序,具体大家看图来体会。而是在预训练和微调或调优阶段后的验证和测试,都要跟随一个决策是否要调整模型,是否要继续进行微调或调优。根据决策来判定是否选择迭代的循环,通过不断的反馈和优化,逐步提升模型的性能和泛化能力,直到涌现出能力,让训练者满意结束训练过程。但让这个过程有个确定起点的话,一定要从模型选择开始。
2. 模型选择:信仰、笃定和坚持

启动训练大模型这个事儿,本身就很疯狂。因为没有人知道结果是否会成功,以及最终训练是否会涌现奇迹。所以模型的选择,说的谦虚一点,是基于模型构建者的先验知识、经验、文献研究和调研,说的玄学一点就是基于一种信仰和笃定。
ChatGPT这种事儿最终能被Samuel Altman 搞成,从他的历史经历来看也是有迹可循的。Sam在个性上是个敢于冒险和不按常理出牌的人。在斯坦福大学学习计算机科学那会儿,刚学了一年,在2005年就退学搞创业了,成立了Loopt,一款基于位置的社交移动应用,作为CEO,几年给公司筹集了3000万美金的风险投资,2012年,它被绿点公司以4340万美金收购,也算是他捞到的第一桶金。Sam接下来从2011年起,成了YC(以投资种子阶段初创公司为业务的创投公司)的合伙人。2014年,Sam被任命为YC的总裁,并开始大刀阔斧,愿意投资和推动新的、未经证实的技术,准备将YC扩大到每年资助1000家初创公司,尤其是“硬科技”公司,而OpenAI就是2015年他和几个行业大佬联合资助起来的,致力于训练人工智能,让人工智能走进人类,试图创建并推广友好的人工智能,以造福所有人,实现智能公平。并很快在2015年就筹集了10亿美金。2019年,Sam笃定大模型一定能搞成,毅然决然离开YC,专注于OpenAI。
Transformer模型在谷歌大脑2017年发布开源的时候,应用的场景是自然语言处理(NLP) 的机器翻译和时间序列预测任务。Sam等人坚信Transformer更适合并行化,允许在更大的数据集上进行训练,这就直接导致了预训练系统的发展。
3. 数据预处理:剔除“脏”数据

有了模型,就要考虑怎么去找数据训练了。这可不是随便在互联网上找到海量数据,然后不分青红皂白就开始训练的。根据国际数据公司IDC的估计,截至2020年,全球数字宇宙的大小为44 Zettabytes(其中1 Zettabyte等于10亿 Terabytes),其中文本、图像和视频等非结构化数据占据了绝大部分。具体来说,据IDC估计,非结构化数据占据数字宇宙的80%以上,其中视频数据占比最高,约为60%。据统计,截至2020年,全球每天产生的文本数据量约为50万亿字节,这相当于每天产生50亿部普通手机的存储容量;而每天上传到YouTube的视频数据量约为500小时,相当于每分钟上传约300小时的视频。如果要把这些数据都学习了,不是不可能,但是也没有必要。
人类的信息有很多,有些信息是正确信息,有些是错误信息,有些是噪声数据。有些信息带有明显的恶意或者逻辑漏洞。如果不分青红皂白,让AI自己去训练自己,可能会在训练数据这个环节就会失控,表现不如预期甚至出现偏差和过拟合等问题。因为“脏”数据,自然不会学出一个理想的模型和能力沉淀。因此,在选择训练数据时,需要尽量筛选和清洗出具有代表性和高质量的数据,从而提高模型的表现和泛化能力。
关于GPT-4学了多大当量的数据并未公开,但是GPT-3学了45TB的文本数据。主要来源于:
- Common Crawl:提供了包含超过50亿份网页数据的免费数据库。有超过7年的网络爬虫数据集,包含原始网页数据、元数据提取和文本提取。
- Wikipedia:网络维基百科,目前有超过1亿的条目项。
- BooksCorpus:由100万本英文电子书组成的语料库。
- WebText:一个来自于互联网的语料库,其中包含了超过8亿个网页的文本内容。
- OpenWebText:类似于WebText,但是包含的文本数据更加规范化和质量更高。
- ConceptNet:一个用于语义网络的数据库,其中包含大量的语言学知识。
- NewsCrawl:从新闻网站收集的大量新闻文章的集合。
- Reddit:一个包含了大量用户发布的信息的论坛网站。
但不能简单的运用拿来主义。这种原始数据,是不能直接进入训练的,还至少要经过以下四个数据预处理阶段,才可以进入到预训练环节:
数据清理(Data Cleaning):处理数据中存在的错误、缺失或不一致的部分,包括删除重复数据、处理缺失值、修复错误数据或调整数据格式等操作。数据清理旨在确保数据的准确性和一致性,以避免对模型训练产生不良影响。
去除噪声(Noise Removal):在数据中可能存在一些无关紧要或错误的信息,被称为噪声。去除噪声的过程是识别和过滤掉这些噪声数据,以提高数据的质量和模型的性能。噪声可能包括文本中的标点符号、停用词、拼写错误、不一致的格式等。通过去除噪声,可以减少对模型的干扰,提高模型对真实信号的学习能力。
标准化(Normalization):标准化是将数据转化为统一的标准尺度的过程。这对于具有不同尺度或分布的特征数据非常重要。标准化可以确保不同特征之间的数据具有可比性,避免模型在处理数据时对某些特征给予不合理的权重。常见的标准化方法包括将数据缩放到特定的范围(例如0到1之间)或者使用均值和标准差进行标准化。
分词(Tokenization):前文已经说了,token是指在信息数据处理中的最小单位,文本数据的预处理中,一个常见的步骤是将原始文本拆分成一个个token,这个过程称为tokenization。目的是将连续的文本序列划分为离散的单元,例如单词、子词或字符。这样做的好处是将文本转换为机器可以处理的离散表示形式。在深度学习模型中,tokenization通常是将文本转换为数字表示的第一步。每个token都被赋予一个唯一的整数编号,这个编号会作为模型输入中的一个特征向量的一部分。
4. 预训练:反向传播算法(Backpropagation)

在数据开始预训练之前,需要先定义损失函数。损失函数是衡量模型预测结果与实际目标之间差异程度的指标。确实,较小的损失函数值表示模型在训练数据上的拟合效果较好,也就是更好地学习了训练数据的内容。在训练过程中,我们的目标是最小化损失函数的值。通过调整模型的参数,使损失函数达到最小值,即实现了对任务的最佳拟合。
在训练过程中,通过计算损失函数相对于参数的梯度,可以了解每个参数对损失函数的影响程度。梯度告诉我们应该如何更新参数值来最小化损失函数。当梯度接近零时,表示损失函数达到了一个局部最小值或平稳点,这可能意味着模型已经收敛到一个较好的状态。这样的情况下,训练可以被认为是相对顺利的。然而,并不是所有情况下梯度接近零都代表训练的顺利进行。在深度学习中,模型可能会遇到鞍点或局部最小值,并且梯度可能会陷入平原地带。此时,某些维度上的梯度接近零,但并不表示找到了全局最小值。鞍点是指在某个位置上,沿一些维度上的梯度是零,但沿其他维度上的梯度不为零的点,甚至其他维度梯度可能仍然有较大的值,说明还有改进的空间。
这个损失函数梯度收敛的过程,除了刚才说的鞍点和局部最小值,还可能遇到梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient),上文已经说过这两个问题代表着什么,以及怎么去应对,这里就不再赘述。
在神经网络中,损失函数梯度收敛的过程是通过反向传播算法(Backpropagation)实现的。反向传播算法(Backpropagation)是指在神经网络中,通过计算损失函数对网络参数的梯度,并将梯度信息从输出层向输入层进行传递的过程。它基于链式法则,通过将梯度从输出层逐层反向传播至输入层,计算每个参数对损失函数的贡献,并利用梯度信息更新网络参数,从而最小化损失函数。反向传播算法用于训练神经网络,通过调整参数使得预测结果与真实标签更接近。
这个过程被很多人戏称为炼丹。在预训练阶段,模型通过大规模的无监督学习来学习语言模型的结构和表示。这个阶段的目标是让模型在未标记的数据上进行自我训练,从中学习到语言的统计规律和语义信息。在这个过程中,模型有机会发现并表现出一些意想不到的能力,这就是“涌现”了。具体来说,当模型规模扩大、参数增多时,模型可能会表现出更好的泛化能力、更高的性能或具备某些令人惊讶的特征。这种涌现现象可能与模型内部的复杂交互和表示能力有关,模型在训练过程中学习到了隐藏的结构或规律,从而表现出超出预期的能力。而作为一种惊喜,“涌现”不能自我展示,还得需要在验证环节被发现。
5. 验证和测试阶段:发现“涌现”的激动
在验证和测试阶段,研究人员和开发者会对训练得到的模型进行评估和验证。一般大模型的验证会分为可塑性、可供性、可用性、可信性和可替代性五个大类26个细分指标:
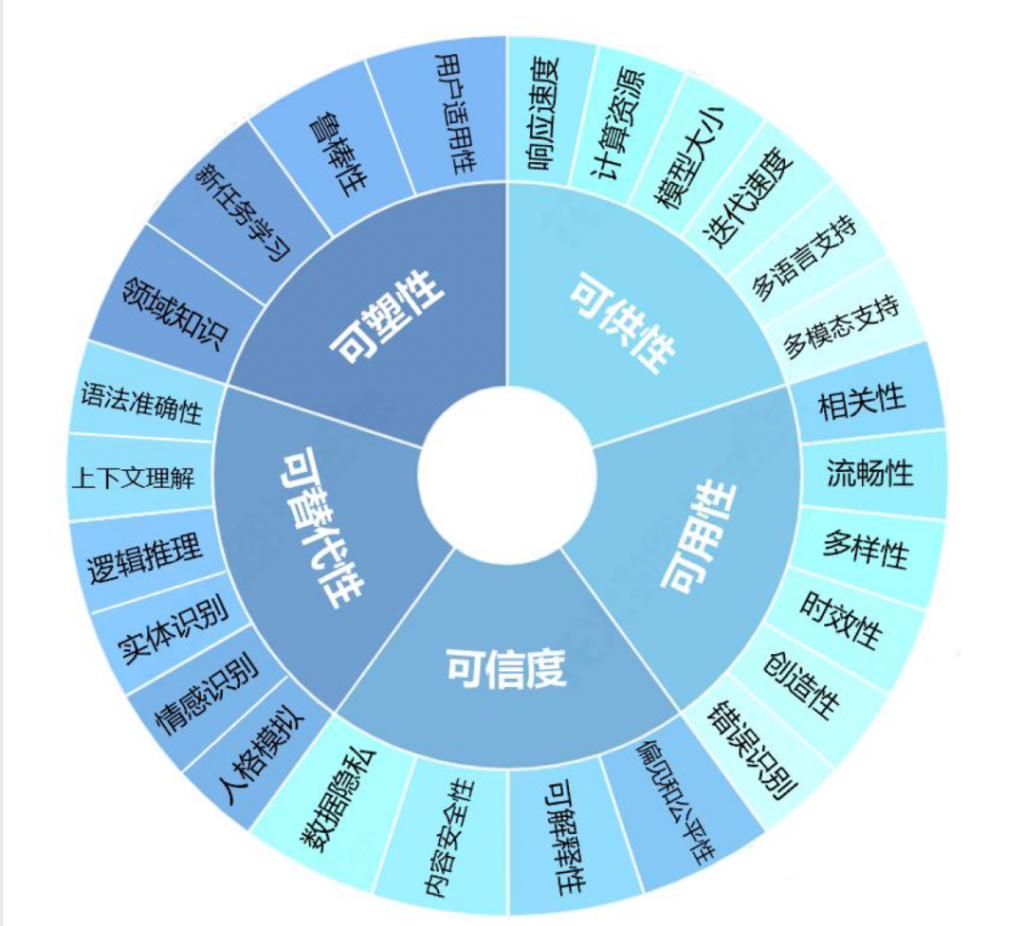
在测试和验证中发现涌现具有偶然性,但也不是一点儿不能预测,所以在测试用例的设计时候,能够足够大胆,预估到可能“涌现”的方向,而提前做好准备。智愿君下面会列出来一些可能涌现的能力,但现实场景可能远远比这个要复杂:
高阶推理能力:大型语言模型在经过训练和优化后,可能展现出对高阶推理任务的能力。这包括对因果关系的理解、扰动变量分析、反事实推理等。模型可以在文本中寻找关联,并推断出复杂的逻辑关系,从而回答复杂的问题。
去除噪声和问题定位:在训练过程中,模型可能学习到了如何去除输入中的噪声,并从复杂的问题中定位和理解问题的根源。这使得模型能够更好地理解用户的意图,并给出准确和有针对性的回复。
自我修正能力:大型语言模型可能具有一定的自我修正能力。通过与用户的交互和反馈,模型可以不断学习和纠正自己的错误,并提供更准确的回答。这种自我修正能力可以帮助模型逐步改进,并提供更高质量的输出。
灵活应对知识盲区:模型在训练过程中可能遇到知识盲区,即对某些领域或主题的了解有限。然而,通过涌现,模型可能能够从已有的知识中推断和应用相关信息,填补知识盲区并给出合理的回答。
知识嵌入、想象力和创造力:模型在训练过程中可能学习到了丰富的知识,并能够将这些知识嵌入到生成的回答中。这使得模型能够展示出一定的想象力和创造力,生成丰富多样的文本,并提供更加富有表现力的回复。大型语言模型可以通过知识图谱、外部知识库等辅助信息,加深对知识的理解和应用。它可以从知识库中检索和整合信息,丰富回答的内容和准确性。
社交和情感智能:大型语言模型可以对情感和情绪进行理解和生成。它可以识别和表达情感色彩,并与用户进行情感交流和互动,从而提供更加个性化和情感化的回复。涌现还可能表现为模型能够根据上下文进行适应性回复,并生成多样性的输出。模型可以根据对话的进行和用户的需求,灵活地调整回复的风格和内容,提供更加个性化和多样化的回答。在处理复杂对话和语境理解方面,模型可能展现出更强的能力。它可以从多个回合的对话中提取关键信息,并进行语义上的深入理解,从而给出更加准确和连贯的回复。
倾向性调控和自我监控:大型语言模型可能具备一定的倾向性调控和自我监控能力。它可以根据用户的需求和要求,调整回复的倾向性和风格,并对自己的输出进行监控和评估,以确保回复的质量和合理性,并坚守某些原则,不会被使用者欺骗而给出违反基本价值观和伤害人类的回复。
多模态能力:大型语言模型不仅可以处理文本输入,还可以与其他模态数据(如图像、语音、视频等)进行交互。模型可以通过学习多模态数据的表示和关联,展现出理解和生成多模态内容的能力。
增量学习和在线学习:大型语言模型可以具备增量学习和在线学习的能力,即在不中断模型服务的情况下,通过逐步接受新数据进行训练和更新,以不断改进模型的性能和适应新领域的需求。
增强学习:大型语言模型可以结合增强学习技术,在与环境进行交互的过程中,通过试错和奖励机制来改进模型的表现。这使得模型能够在特定任务或领域中进行优化和自我调节。
跨任务迁移:大型语言模型在完成一个任务的训练后,可以通过迁移学习的方式将学到的知识和模型参数应用到其他相关任务上,从而加速其他任务的训练和提升性能。
元学习和自适应学习:大型语言模型可以通过元学习和自适应学习的方法,快速适应新的任务或环境。模型可以从先前的训练和经验中快速学习到新任务的模式和规律,从而实现快速上手和灵活应对新情境的能力。
6. 微调:强化学习是要寻求特定领域的最优解
如果我们的最初目的就是希望ChatGPT就是和我们侃大山,天马行空,停留在所谓的通用模型的状态,可能我们不会进入到微调和调优阶段。但如果我们是完美主义者,我们希望ChatGPT可以在很多有最优解的问题上能回答得很完美,强化学习就用的上了。
而无监督学习的硬伤就是通常是通过最大化数据的某种统计属性来学习模型。以一种通用的方式学习数据的分布和特征,缺乏领域或任务特定信息,说白了就是万金油之后,容易产生不必要的瞎联系,或者说一本正经地胡说八道。
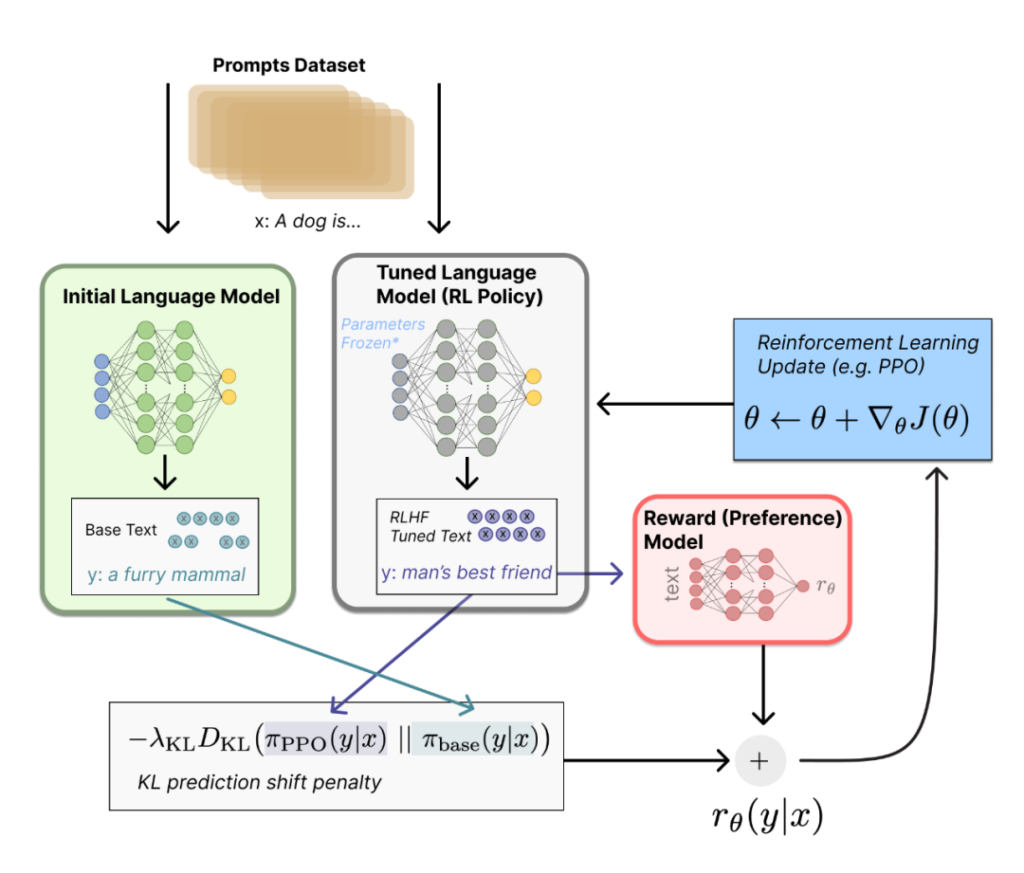
要想让ChatGPT在很多专业领域表现出色,基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)训练的微调和调优就显得格外重要。RLHF在模型预训练的基础上,通过与人类进行交互,收集人类专家的反馈信息,以指导模型的微调和调优。通过将人类专家的知识和判断引入模型训练过程中,可以根据人类反馈的奖励信号对模型进行优化,使模型能够在特定环境下做出“最优决策”。我之所以在这里给“最优策略”打引号,是因为这是在部分专家反馈基础上的最优策略。如果我们加大人类专家反馈的力度,花费更大的成本进行微调,可能最终的效果会更为理想,到这个阶段,就不是纯技术问题,而上升为一个密集劳动型的动作了。RLHF的一个主要问题是可扩展性,即如何应对大规模的训练数据和计算资源需求。此外,这种训练过程可能是缓慢且昂贵的,需要耗费大量的时间和资源。也正是由于这个原因,OpenAI更愿意把这部分能力通过API或者Plugin插件开放出来,众人拾柴火焰高, 让更多的垂直领域的产业发挥作用,在各自的领域深耕。经过这种微调后,GPT的专业领域技能就会越来越丰富,越来越优秀。
微调和调优还有一个很重要的点就是价值学习。AI系统如何与人类价值观保持一致,能够在复杂的动态环境中与人类价值观对齐,符合人类伦理、法律准则并尊重个人隐私和防止坏人用AI进行欺诈。这就需要不停地对AI进行微调和调优,来完善和修订在实际运作中的各种漏洞和表现。从这个维度来看,微调和调优是一个永无止境的工作,不存在一劳永逸。当然,这里面还存在另外一个风险,就是人类反馈的质量和一致性可能会因任务、界面和个体偏好的差异而有所不同。如果人类反馈缺乏公正性或不正确,那么模型也有可能学到错误的东西,这种情况被称为人工智能偏见。特别是当反馈来自具有特定价值观的人群时,这种偏见可能表现得尤为明显。如果最终模型的使用人群范围的复杂度远远大于RLHF的单一价值观,就会出现非常糟糕的使用体验。所以微调和调优,也是一个双刃剑,如果处理不好,害人害己。
7. 大模型训练的未来:“灭霸”还是“女娲”

大模型的训练当前的基本流程,未来一定是会调整的。因为当下,大模型的“炼丹”是离线学习,也称为批量学习(Batch learning),使用固定的数据集进行训练和学习,而不是在实时数据流中进行更新。而未来是一定要走到在线学习(Online learning)的道路上的,能够在不断到达的数据流中进行实时学习和适应。只有后者,才有可能成为真正的通用人工智能,适应人类社会的高速发展的实时性,更好地应对动态和快速变化的环境。
所以说,即便演进到通用人工智能,对这个模型的训练,也是一条永无止尽的路。只要人类社会还在进化,通用人工智能就需要考虑如何跟进人类的集体智能,不停地将新学到的人类只是和技能迁移到新任务或领域中。
而且未来大模型的交互或者表达的手段会更加多模态化,不仅仅局限在文字、图形。因此,大模型的训练必然会整合不同领域的知识和技术,包括自然语言处理、计算机视觉、语音识别等,以构建多模态学习的能力。
当然,我们仍需要谨慎乐观,如果未来要面对人机共生,就需要慎重面对强化道德伦理和人工智能政策,因为我们要创造的不是灭霸的响指,而是女娲造人和盘古开天。