河套 IT TALK 73:(原创)解读老黄与 Ilya 的炉边谈话系列之二——信仰、准备、等待机会的涌现(万字长文)

一个月前,就在GPT 4发布的第二天,同时也是英伟达(NVIDIA)线上大会的契机,英伟达的创始人兼CEO黄仁勋(”Jensen” Huang)与OpenAI的联合创始人兼首席科学家伊尔亚-苏茨克维(Ilya Sutskever )展开了一次信息量巨大的长达一个小时的“炉边谈话”(Fireside Chats)。期间谈到了从伊尔亚-苏茨克维早期介入神经网络、深度学习,基于压缩的无监督学习、强化学习、GPT的发展路径,以及对未来的展望。相信很多人都已经看过了这次谈话节目。我相信,因为其中掺杂的各种专业术语和未经展开的背景,使得无专业背景的同仁很难彻底消化理解他们谈话的内容。本系列尝试将他们完整的对话进行深度地解读,以便大家更好地理解ChatGPT到底给我们带来了什么样的变革。今天,就是这个系列的第二篇:信仰、准备、等待机会的涌现。

对话译文(02):
黄仁勋:AI 大爆炸!快进到现在,你来到了硅谷,你和一些朋友一起创办了 OpenAI,成为首席科学家。关于在 OpenAI 开展哪些工作,你最初的想法是什么?因为你们做了一些事情,你们的工作和发明,带来了 ChatGPT 时刻。但是,最早的源动力是什么?你是怎么让它实现的?
Ilya Sutskever:在刚开始的时候,我们显然不是100%清楚如何去推动它。而且当时这个领域,与现在截然不同。现在我们拥有这些惊人的工具,这些惊人的神经网络,来做一些难以置信的事情。
但是回到2015 – 2016年,回到2016年初,当我们开始创业时,整个事情看起来很疯狂。当时,这个领域的研究人员要少得多,可能比现在少100-1000倍。那时可能只有100个人,他们中的大多数人在 Google / DeepMind 工作。然后有些人开始学习这些技能,但仍然非常稀缺。
我们有两个很大的初始想法,在 OpenAI 刚开始的时候。这些想法的持久力,一直伴随着我们到今天。我现在会描述一下它们。第一个想法是通过压缩上下文进行无监督学习(Unsupervised Learning)。
今天,我们想当然地认为无监督学习很简单。你只需对所有东西进行预训练,一切都完全按照你的预期进行。但在2016年,无监督学习是机器学习中一个尚未解决的问题,没有人知道该怎么做。Yann LeCun 到处发表演讲,说监督学习面临巨大的挑战。我真的相信好的数据压缩将产生无监督学习。
直到最近,在描述无监督学习的工作原理时,我们还不会广泛地提及压缩(Compression)。很多人突然了解它,是因为 GPT 模型实际上压缩了训练数据。你可能还记得 Ted Chiang 在《纽约时报》上的文章,它也提到了这一点。
但是从数学意义上讲,训练这些自回归生成模型(Auto-Regressive Generative Models),会压缩数据。你可以直观地看到它们为什么会起作用。如果你将数据压缩得非常好,你就能够提取其中存在的所有隐藏信息,这就是关键。
因此,这是我们真正兴奋的第一个想法,这导致了 OpenAI中关于情感神经元(Sentiment Neuron)的一些工作,我将非常简要地提到这一点。这项工作在机器学习领域之外可能并不为人所知,但它非常有影响力,尤其是在我们的思想中。
这项工作,就像那里的结果一样,当你训练一个神经网络时,它不是 Transformer,而是在 Transformer 之前的模型。如果很多人记得的话,那是小型循环神经网络(Recurrent Neural Networks),就是LSTM(Long Short-Term Memory)。
黄仁勋:完成一些序列到序列的工作,我的意思是,这是你们自己做的一些工作。
Ilya Sutskever:因此,我们用相同的 LSTM 稍微调整一下,来预测 Amazon 评论的下一个字符。我们发现如果你预测下一个字符足够好,就会有一个神经元在 LSTM 内对应于它的情绪。这真的很酷,因为它展示了无监督学习的一些效果,并验证了能够预测下一个字符,预测下一个想法。压缩具有发现数据中秘密的特性。这就是我们在这些 GPT 模型中看到的,对吧?你进行训练,人们说是统计相关性。
黄仁勋:在这一点上,对我来说,它直接打开了我从哪里获得无监督学习数据的整个世界。因为我确实有很多数据,如果我能预测下一个字符,我知道真相是什么,我知道答案是什么,我可以用它训练一个神经网络模型。这个观察结果,以及其他技术、其他方法,打开了我的思路,让我意识到世界将从哪里获得所有无监督学习的数据。
Ilya Sutskever:我想是这样的。换一种说法,我会说在无监督学习中,困难点不在于从哪里获取数据,尽管现在也有这个问题。更多的是关于为什么要这样做?困难点是意识到训练这些神经网络以预测下一个token 是一个值得追求的目标。但实际上它并不那么明显,对吧?所以人们没有这样做。
但是情感神经元起作用了,我想说 Alec Radford 是真正推动许多进步的人。那时的情感神经元,这是在 GPT-1之前,它是 GPT-1 的前身,它对我们的思维有很大的影响。然后,Transformer 出来了。我们立即想到,Oh my God,就是它了。于是,我们训练了 GPT-1。
黄仁勋:在这个过程中,你一直相信,增加规模会改善这些模型的性能。更大的网络,更深的网络,更多的训练数据将使它的规模变得更大。OpenAI 写了一篇非常重要的论文,讨论了模型规模变化规律,以及模型大小和数据集数量之间的关系。当 Transformer 出现时,它给了我们在合理时间内训练大模型的机会。但对于模型规模变化规律,以及模型大小和数据集关系的直觉,相对于 GPT-1、2、3,哪个先出现?你有看到 GPT-1 到GPT-3 的发展路径吗?还是先有模型规模变化规律的直觉?
Ilya Sutskever:直觉。我想说,我有一个很强烈的信念,模型规模越大越好。在 OpenAI,我们的一个目标是找出增加模型规模的正确途径。OpenAI 一开始就对增加模型规模抱有很强的信念,问题是如何准确地使用它。因为我现在提到的是 GPT,但是还有另外一条非常重要的工作路线,我还没有提到。
智愿君:让我们继续解读老黄和Ilya炉边谈话的第二段对话,信息量同样满满:
为什么不是Google/DeepMind?

Ilya提到在2016年,那个时候OpenAI才刚刚成立,DeepMind就已经凭借围棋机器人AlphaGo一炮走红。而且正如Ilya提到的,当时绝大多数神经网络和深度学习的大牛们都在Google/DeepMind就职。让我们不禁唏嘘,为什么开发出ChatGPT的不是Google/DeepMind呢?甚至Ilya连带他的导师,不也是一搞完AlexNet,就被Google收编了吗?如果这种预期表现完全不符合人才分布的逻辑,难道是运作机制上出现了问题?

还记得2016年5月份,新官上任仅数月的谷歌CEO桑达尔·皮查伊(Sundar Pichai),在谷歌I/O开发者大会上发出了谷歌的AI宣言:谷歌将从一家移动优先(Mobile First)的公司,升级为一家“人工智能优先”(AI-first)的公司。

回想当时,意气风发,不可一世的巨无霸Google,在AI方面,俨然分成红蓝两个团队,相对独立运作:一个是Google Brain(谷歌大脑)为代表的深度学习团队Google AI(红队),由Jeff Dean带队。这里面不仅仅有斯坦福大学教授华人吴恩达(Andrew Ng),还有上文提到的Geoffrey Hinton,研究的内容重点是渐进式产品改进,立即产生商业价值。所以这个团队在图像增强、谷歌翻译、机器人自动化、TensorFlow以及后面Ilya也提到了的直接改变OpenAI命运的Transformer。注意,后面两个项目可都开源了哈,当然Google开源也是有小九九的,开源也就是意味着可以去雷达扫描行业大牛,只要发现代码核心贡献者,就直接收编。第二个团队就名声显赫了,在2014年被Google收购的DeepMind(蓝军),首席执行官是 德米斯·哈萨比斯(Demis Hassabis),重点研究领域是深度强化学习,目标很明确,就是要给出最优解,并坚定地信仰通用人工智能AGI,不求短期商业回报。所以一系列的Alpha项目都是这样的逻辑,从AlphaGo(围棋冠军)、AlphaFold(蛋白质折叠预测最准确结构)、AlphaStar(寻求星际争霸游戏夺冠)、AlphaCode(寻求竞技类编程夺冠)。
之所以相对独立,原因是DeepMind作为一家2010年成立的人工智能非盈利机构,自创立第一天,便以“解决智能”为愿景,希望能够用AI造福人类。德米斯·哈萨比斯是AGI最坚定的信仰者。但也深深地忧虑AGI为人类社会带来无限想象的背后,有着难以预测的未知阴暗面,所以要“解决智能”,“控制智能”,绝对不能落入打指响的“灭霸”手里。DeepMind用尽各种办法,保持自身第三方非盈利机构的独立性和羽毛的洁净。DeepMind与Google的协议就是Google为DeepMind提供资金,并获得其技术的独家许可,条件是Google不能跨越某些道德红线,例如将DeepMind技术用于军事武器或监视。不过Google没两年就在Maven项目上食言了,这是另外一个话题,不再展开。
从项目分布和红蓝军的责任分工来看,确实没有大的毛病。所以我觉得,最大的原因,既不是人才分布逻辑问题,也不是运作机制问题。而关键是产品定位问题。Google从一开始就不看好什么聊天机器人这个领域,这才是为什么和ChatGPT失之交臂的核心。
可能你会说,DeepMind不是有一个Sparrow聊天机器人吗?我承认,确实有这么一个“内测版”,同样基于Transformer 机器学习模型架构的深度神经网络,它使用人类反馈强化学习(RLHF) 进行训练,由 DeepMind 的Chinchilla AI预训练大型语言模型(LLM) 进行监督微调,通过奖励模型来捕捉人类的偏好,该模型具有 700 亿个参数。遗憾的是,由于不是核心项目,所以,DeepMind没有把宝押在这个上面,所以表现不佳,也就没上心,束之高阁了。所以回过头还是产品定位问题。
就像你手头有很多的项目,抓大放下就需要做排序和筛选,而OpenAI没那么多选择,他们重点就押在一个核心项目:GPT,从1做到4。孤注一掷,瞄准AGI的最终目标,只做一件事:加大模型规模。所以,选择太多有的时候容易挑花眼,还真未必就是好事。特别是针对当时普遍不被看好的一个方向,去使出浑身解术,不惜代价,很高的概率会撞南墙,但也会小概率造就英雄。这个时候,是人性的考验了。埃隆马斯克也是典型的这号人。
不过也不要小觑Google/DeepMind的后发力量,瘦死的骆驼比马大。“DeepMind+谷歌”才是最应该做出ChatGPT的黄金组合——2017年,DeepMind最早提出了RLHF(人类反馈强化学习)概念,这是ChatGPT涌现强大对答能力的关键一步;同年6月,Google发布NLP领域全新架构Transformer,成为后来所有LLM(Large language model,大语言模型)的基础架构,也是OpenAI整个GPT系列模型的基石。
之前如果还存在DeepMind关于独立运营的抗争,以及Google AI这边还存在给DeepMind的烧钱项目输血而产生的“DeepMind吃Google的饭,砸Google的锅”的抱怨。那是因为没有共同的敌人,现在竞争对手出现了,OpenAI就在那里,ChatGPT就在那里,还有什么好犹豫的,赶紧力出一孔呗。所以Google Brain在2023年4月并入DeepMind,相信不远的将来,做出来足以和ChatGPT抗衡的产品,也不会让人感到诧异。
通过压缩上下文进行无监督学习
这里有两个关键词,一个是无监督学习,一个是压缩。上文,我们其实已经简单解释过了什么是无监督学习。为了更生动描述这个,我可以拿教育孩子来类比。不会自学孩子,就需要监督学习,也就是老师需要手把手去教。老师要给孩子搞题海战术,每套卷子都有标准答案,然后孩子做完题对答案,判分对错,然后孩子还不懂去总结规律,就不停刷题,直到最后熟练掌握。监督学习有个很大的问题,就是得准备模拟卷子,而且,标准答案还得确保正确,否则就会出现孩子学习效果降低。
无监督学习就不需要玩题海战术了,把课本内容告诉孩子,孩子自己去看书,去自学和发现规律,他们自己总结,归纳,并不是我们直接告诉他们什么事对的或者错的,让他们去探寻事物的本质和规律,真正做到融会贯通。其实要提炼逻辑的话,无非是要求学生掌握归纳和演绎的能力,最终能达到无师自通的效果。
不难想象,如果我们希望AI帮助完成一个相对简单的任务,监督学习的效率肯定是最高的,如果我们要培养的是一个通用人工智能AGI,那是肯定要坚定地站在无监督学习的立场毫不动摇的。
之所以需要压缩上下文,其实就是信息本身就带有冗余,语言文字也不例外。如果不压缩,计算成本会很高,而去除冗余和无用的信息,压缩会降低输入维度,更容易对应到合适的模型,大幅度提升模型的性能。通过压缩上下文信息,将输入文本表示为低维度的向量,然后使用这些向量来预测下一个单词。这里的上下文是指在给定位置之前和之后的单词。在实践中,通常使用自编码器(autoencoder)来进行上下文压缩。自编码器是一种无监督学习算法,它能够学习将输入数据压缩成低维度的向量,然后再将其解压成原始的输入数据。为了在自编码器中进行上下文压缩,模型被训练来最小化输入和输出之间的重构误差。也就是说,它会尝试在保留尽可能多的上下文信息的同时,将输入文本表示为一个尽可能小的向量。一旦模型训练完成,这些向量可以被用作预训练语言模型的输入,来学习单词之间的关系。
Yann LeCun

上文其实我们对这位大神我们也提过一嘴,就是他和Yoshua Bengio和Geoffrey Hinton一起获得了 2018 年图灵奖(通常被称为“诺贝尔计算奖”)。不过和另外两位不同,他是法国人计算机科学家。从Ilya的谈话中,我们也了解到,之所以坚定不移走无监督学习,也是受到了Yann LeCun的影响。Yann LeCun作为深度学习领域的著名科学家,在人工智能领域拥有广泛的知名度和影响力。他是纽约大学Courant研究所的教授,同时也是Facebook的首席AI科学家。
Yann LeCun曾经领导过多个顶尖研究团队,如AT&T贝尔实验室的神经网络研究组,他是卷积神经网络(CNN)的创始人之一,并在计算机视觉、自然语言处理等领域做出了许多开创性的贡献。
Yann LeCun倡导深度学习的可解释性和对生物学的启示,提出了许多创新性的方法,如卷积神经网络(CNN)和深度置信网络(DBN),这些方法在计算机视觉和自然语言处理等领域的应用广泛。
在深度学习领域,可解释性一直是一个重要的问题,因为深度学习模型的复杂性使得人们很难理解其内部运作原理。Yann LeCun主张使用可解释的模型,以便更好地理解深度学习系统的决策过程。他提出了一种称为“卷积神经网络”的神经网络结构,该结构的灵感来源于人类视觉系统,这种结构不仅有效地解决了图像识别问题,还使得网络的可解释性得到了显著提高。
Yann LeCun也关注生物学的启示,他认为人类大脑的神经网络结构是一种非常有效的模型,并且认为深度学习的发展应该紧密跟随生物学的研究。他提出了一种称为“卷积稳态网络”的新型神经网络结构,该结构受到人脑皮层神经元的启发,并具有类似的层次结构和局部连接特性。
不仅仅是技术方面的思考,Yann LeCun还对科技与社会的关系提出了反思。他指出,人工智能技术的发展必须与人类价值观和伦理原则相结合,以确保其在推动社会进步的同时不会对人类造成伤害。他还担任了Facebook的AI实验室负责人,致力于开发人工智能技术,并重视将其应用于社会福利领域,如医疗保健和教育。
迷科幻的创业大佬们

Ted Chiang是一位美国科幻小说作家和翻译家,他以其高质量的科幻小说著称。他曾多次获得雨果奖、星云奖等重要科幻文学奖项,并被誉为“科幻小说之王”。他的作品常常涉及哲学、伦理、宗教、科学等深度主题,引人深思。他的作品被翻译成多种语言,在全球范围内拥有广泛的读者群体。
Ted Chiang在2019年写了一篇题为《关于人工智能的真相,一份报告和一篇小说》(”The Truth of Fact, the Truth of Feeling”)的文章,发表在《纽约时报》上。这篇文章探讨了人工智能的历史、现状以及未来发展方向,并提到了压缩在人工智能中的重要性。文章中,Ted Chiang指出,从信息论的角度来看,压缩和人工智能是紧密相关的。在这篇文章中,Ted Chiang提出了一个思想实验,探讨了对记忆进行无损压缩的可能性以及与人类记忆和身份认同之间的关系。这篇文章在人工智能领域引起了广泛的讨论。Ilya Sutskever所说的GPT模型压缩训练数据的部分可能指的是这篇文章对于压缩在人工智能中的论述对于GPT模型的启发。
我们不难发现硅谷很多创业大佬都是科幻小说家的忠实读者,并且深受到科幻小说的启发和印象,我随便谈一些例子:
亚马逊的创始人贝索斯是一位著名的科幻小说迷,他曾表示,科幻小说对他的思考方式和商业决策产生了很大影响。
苹果公司的创始人乔布斯也是一位爱好科幻小说的人,他在演讲和采访中经常引用科幻小说的思想。
Meta(前Facebook) 的创始人扎克伯格也是一位科幻小说迷,他曾表示他最喜欢的书之一是 Orson Scott Card 的《安德的游戏》。
PayPal 的联合创始人之一 彼得·蒂尔是一位重度的科幻小说读者,他在很多场合都会提到科幻小说对他的影响。
伊隆马斯克同样也是个科幻小说迷,他的脑机接口项目Neuralink就是受到了科幻小说的启发。马斯克认为科幻小说是激发人们对未来的想象力和创新能力的重要来源,他认为科学家和工程师们应该把科幻小说中的想法变成现实。
我觉得这不是一个偶然现象,只有对科幻执着而痴迷的热忱,才能从中汲取灵感,运用到自己的创业和商业实践中,想尽办法让科幻变为现实,最终成为硅谷的传奇。(突然想到,以后有机会是不是再出一期关于科幻小说如何推进人类发展的文章?)
自回归生成模型
正确理解自回归生成模型(Auto-Regressive Generative Models)这个词儿,可以把它先拆解为两个词儿,一个是自回归模型,一个是生成模型。
自回归模型是指,模型的生成过程是基于先前生成的一些内容来生成下一个内容,这个过程中,模型使用了自回归的方法。例如,在自然语言处理中,一个自回归模型会根据先前的单词来预测下一个单词,这个模型可以是循环神经网络(RNN)或者Transformer等。
生成模型则是指,模型的目标是生成新的数据,这些数据可以是图片、文本或者音频等。生成模型分为两种类型:无条件生成模型和条件生成模型。无条件生成模型是指,生成的数据不受任何条件的限制。条件生成模型则是指,生成的数据受到某些条件的约束,例如,在图像生成中,条件可以是图像的标签或者描述等。
因此,自回归生成模型是一类基于自回归方法的生成模型,其生成过程是基于先前生成的一些内容来生成下一个内容,从而生成新的数据。这里的“自回归”表示生成模型输出的每个元素都是由前面生成的元素决定的,因此模型可以被视为是在生成一个序列时不断自我回归。典型的自回归生成模型包括语言模型和图像生成模型等。当训练自回归生成模型时,模型需要学习捕获训练数据的相关特征并生成类似的数据。这意味着模型需要压缩数据中的信息,以便在生成新的数据时使用。因此,Ilya才会说,从数学意义上讲,训练自回归生成模型实际上是在压缩数据。
情感神经元

情感神经元是由 OpenAI 的Alec Radford 牵头开发的一种技术。现在Alec Radford 已经离开OpenAI并自己创办的 AI 研究公司 Machine Learning Research。Ilya对他念念不忘,想必是非常感激他的贡献。
情感神经元(Sentiment Neuron)是一种神经元,它能够捕捉自然语言文本中的情感信息。在自然语言处理任务中,情感分析是一个重要的应用场景,它涉及到对一段文本的情感极性进行分类,例如判断一段文本是积极的、消极的还是中性的。
情感神经元在 GPT-2 模型上进行了微调,以对情感进行分类。在 GPT 中,情感神经元是通过监督学习来训练的。具体地说,GPT 在训练时使用了一个巨大的语料库来预测下一个单词,这个过程是基于自回归模型的。在这个过程中,情感神经元被训练用于预测输入文本的情感极性,例如,它能够判断一个单词或一个短语是积极的、消极的还是中性的。
情感神经元实际上是一个多分类器,它由一个或多个神经元组成,每个神经元代表一种情感极性。在 GPT 中,情感神经元被嵌入到神经网络的最后一层,它可以根据输入文本的上下文来预测情感极性。
通过情感神经元,GPT 能够捕捉到输入文本的情感信息,并生成具有相应情感极性的文本。这使得 GPT 在情感分析、生成式文本摘要等任务中具有很好的表现。

除了情感神经元,还有一些其他的方法可以用来判定对话中对方的情感状态,其中一个比较常见的方法是基于奖励机制(reward-based approach)。奖励机制也恰恰是潜在的竞争对手DeepMind的聊天机器人Sparrow采用的方法。这种方法是通过给对话系统设置一个奖励函数,根据对话系统的回答是否符合预期,来调整奖励的大小。例如,如果对话系统的回答能够让用户满意或者产生积极的情感,那么就会获得较高的奖励;相反,如果回答不能满足用户的需求,或者产生消极的情感,则会受到惩罚。
通过这种奖励机制,对话系统可以逐步学习如何更好地满足用户的需求,并且根据用户的情感状态来做出回答。相较于情感神经元,奖励机制更加灵活,可以根据实际情况进行调整和优化,但同时也需要更多的领域知识和经验来设计合适的奖励函数。
LSTM
LSTM(Long Short-Term Memory)是一种常用于序列数据处理的循环神经网络(Recurrent Neural Network,RNN)模型。相比于传统的RNN,LSTM引入了门控机制,能够更好地处理长序列数据,缓解了梯度消失/爆炸等问题。LSTM是由德国计算机科学家Sepp Hochreiter和Jürgen Schmidhuber在1997年提出的。
LSTM中的关键组成部分是“细胞状态”(cell state)和三个门:输入门(input gate)、遗忘门(forget gate)、输出门(output gate)。细胞状态是网络中的信息“主干”,负责在长时间内保留/遗忘信息。三个门控制信息的输入、遗忘和输出。
具体来说,输入门决定了在当前时刻,哪些信息会被输入到细胞状态中;遗忘门决定了哪些信息需要被遗忘;输出门决定了在当前时刻,哪些信息需要被输出。
LSTM的结构比较复杂,但是能够有效地处理长序列数据,因此在自然语言处理、语音识别、视频分析等领域得到了广泛应用。
Transformer
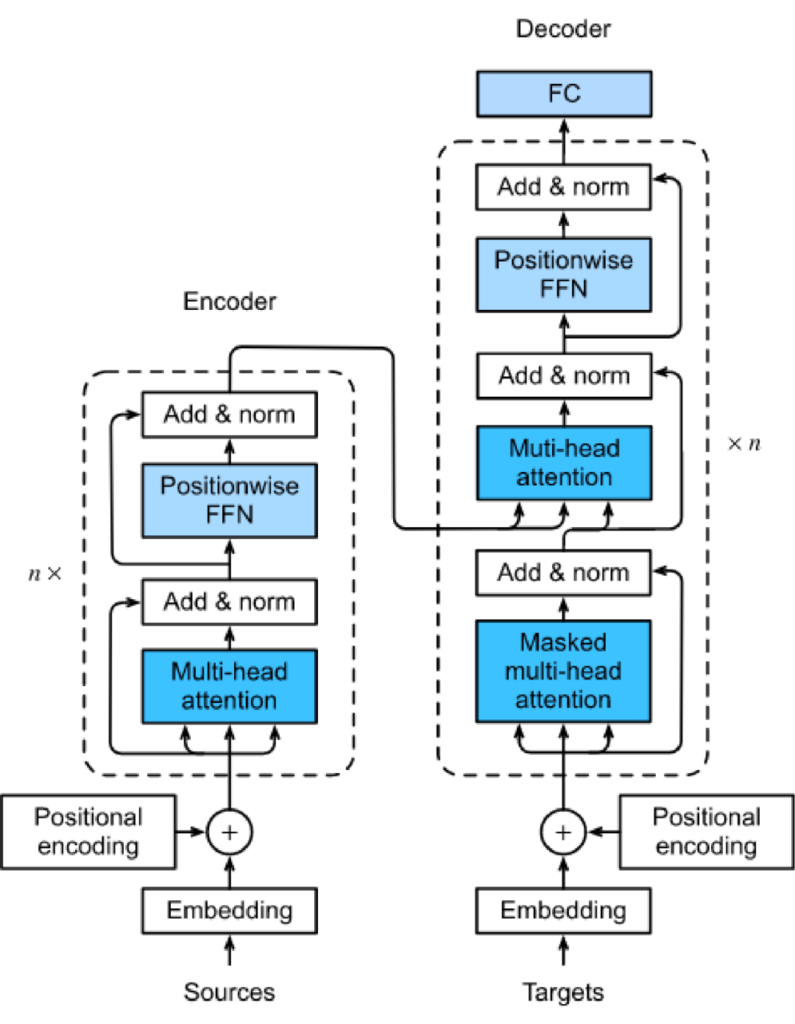
Transformer是一种基于自注意力机制(self-attention mechanism)的深度学习模型,由Google的研究员Vaswani等人在2017年提出,并开源。相对于之前的神经机器翻译模型,Transformer的最大优点是能够并行计算,因此具有极高的训练效率。
在2017年之前,神经机器翻译的主要模型是基于循环神经网络(Recurrent Neural Network,RNN)的编码器-解码器模型。这种模型在输入序列较长时,需要将每个时间步的隐状态都传递到下一个时间步,导致计算量非常大,训练时间也很长。为了解决这个问题,Vaswani等人提出了Transformer模型,使用自注意力机制代替了RNN,从而实现了高效的并行计算。
Transformer模型的成功推动了深度学习在自然语言处理领域的应用,许多重要的自然语言处理任务,如机器翻译、文本生成、问答系统等,都采用了Transformer模型或其变种。其中最为著名的就是OpenAI的GPT模型,它采用了Transformer的变种,并在大规模语料上进行了训练,取得了极高的语言理解能力。
- llya提到GPT最初采用了基于LSTM的架构,但在后来的版本中,转而采用了Transformer。这是因为Transformer在自然语言处理任务中表现更好,并且可以更高效地处理大量的文本数据。同时,Transformer还具有更好的可扩展性,因为它可以轻松地并行化处理大规模数据,而LSTM很难做到这一点。
- LSTM就是一种循环神经网络(RNN),主要用于处理序列数据,如文本或时间序列数据。它的设计中包含三个门(输入门、遗忘门和输出门),这些门控制着信息的流动,以避免梯度消失或梯度爆炸的问题,从而使得LSTM能够处理长期依赖关系。但是,LSTM的计算复杂度较高,且很难并行化。
- 相比之下,Transformer采用了一种基于注意力机制的架构,可以高效地并行化处理序列数据。它不需要像LSTM一样进行逐个时间步的计算,而是直接对所有位置进行操作,利用注意力机制实现信息的传递和加权。这样可以大大提高模型的训练速度和效率。在自然语言处理任务中,Transformer模型比LSTM模型表现更好,因为它可以捕捉长期依赖关系和上下文信息。
大模型炼丹
大模型(large models)是指具有数十亿到数万亿个参数的深度学习模型。这些模型通常需要在具有数百个GPU的计算机集群上进行训练,并具有极高的计算和存储要求。大模型到底有什么效果,说实话,在涌现出现之前,这就跟赌场投币机一个道理,谁都没一个定数,唯有的就是执着的信念。
对ChatGPT来说,大模型的影响主要表现在以下几个方面:
- 更高的生成能力和语言理解能力:随着模型规模的增加,ChatGPT可以处理更复杂的自然语言任务,如生成更流畅、更自然的对话,以及更准确的语言理解。
- 更长的上下文:大模型可以处理更长的上下文信息,使ChatGPT可以更好地理解文本的语义和语境,并生成更加准确的文本。
- 更多的预训练任务和数据:大模型通常需要进行更多、更复杂的预训练任务和数据集的训练,以提高模型的泛化能力和应对多样化的应用场景。
Alec Radford是大模型技术的主要倡导者之一,所以Ilya才提到他的功绩。他的论文《Language Models are Unsupervised Multitask Learners》和OpenAI公司的GPT模型是大模型技术的代表作之一。在情感神经元方面,他也是其中的主要贡献者之一,提出了Sentiment Neuron的概念并在GPT中实现。通过情感神经元,GPT可以学习到文本的情感信息,从而生成更加符合情感倾向的文本。
GPT-2模型问世,就具有15亿个参数,40GB的数据训练量达到第一代GPT的十倍。而GPT-3直接上到 1750 亿个参数。更不要说GPT-4/5到了什么样的恐怖量级。
技术不断迭代,训练所消耗的成本越发高昂,炼丹的成本也就急速攀升,OpenAI当然要非常感谢微软公司的百亿美金资本提升算力。我觉得这个和比特币时代的矿机类似,如果想挖矿,就得要舍得硬件计算能力的投入。(老黄又在偷笑了)
好了,今天我们先解读到这里。下次,我们会继续针对黄仁勋与Ilya Sutskever的“炉边谈话”的其他部分进行解读,敬请期待。