开源鸿蒙内核源码分析系列 | 双向链表 | 谁是内核最重要结构体(转载)
原文来自鸿蒙研究站:http://weharmonyos.com/blog/101.html
鸿蒙研究站网址:http://weharmonyos.com

双向链表是什么?
谁是开源鸿蒙内核最重要的结构体 ?一定是: LOS_DL_LIST(双向链表), 它长这样:
typedef struct LOS_DL_LIST {
struct LOS_DL_LIST *pstPrev; /**< Current node's pointer to the previous node | 前驱节点(左手)*/
struct LOS_DL_LIST *pstNext; /**< Current node's pointer to the next node | 后继节点(右手)*/
} LOS_DL_LIST;在linux 中是 list_head, 很简单,只有两个指向自己的指针,但因为太简单,所以不简单。站长更愿意将它比喻成人的左右手,其意义是通过寄生在宿主结构体上来体现,可想象成在宿主结构体装上一对对勤劳的双手,它真的很会来事,超级活跃分子,为宿主到处拉朋友,建圈子。
双向链表基本概念
双向链表是指含有往前和往后两个方向的链表,即每个结点中除存放下一个节点指针外,还增加一个指向前一个节点的指针, 从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,这种数据结构形式使得双向链表在查找时更加方便,特别是大量数据的遍历。由于双向链表具有对称性,能方便地完成各种插入、删除等操作。
使用场景
在内核的各个模块都能看到双向链表的身影,下图是初始化双向链表的操作,因为太多了,只截取了部分:
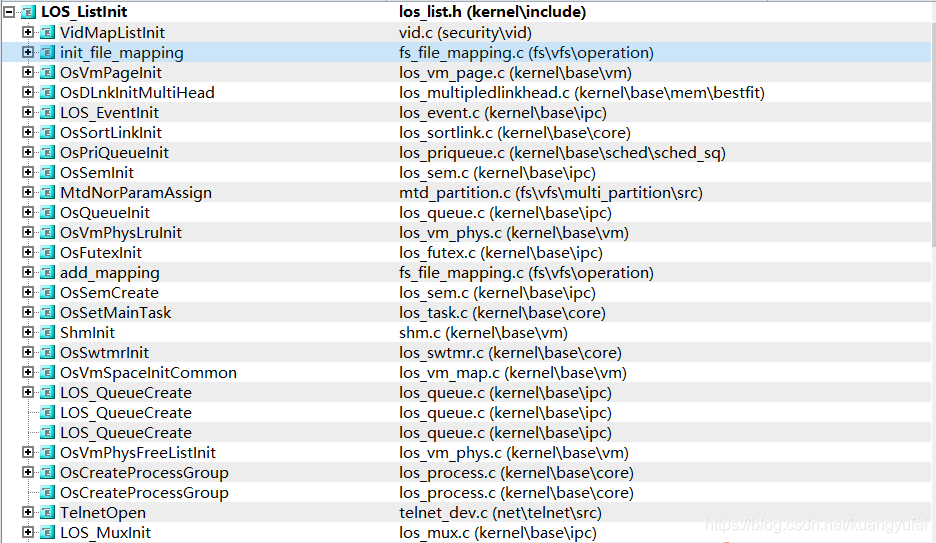
可以豪不夸张的说理解LOS_DL_LIST及相关函数是读懂开源鸿蒙内核的关键。前后指针(左右触手)灵活的指挥着系统精准的运行,越是深挖内核代码越是能体会到它在内核举足轻重的地位, 笔者仿佛看到了无数双手前后相连,拉起了一个个双向循环链表,把指针的高效能运用到了极致,这也许就是编程的艺术吧!
怎么实现?
开源鸿蒙系统中的双向链表模块为用户提供下面几个接口:
功能分类 接口名 描述
初始化链表 LOS_ListInit 对链表进行初始化
增加节点 LOS_ListAdd 将新节点添加到链表中
在链表尾部插入节点 LOS_ListTailInsert 将节点插入到双向链表尾部
在链表头部插入节点 LOS_ListHeadInsert 将节点插入到双向链表头部
删除节点 LOS_ListDelete 将指定的节点从链表中删除
判断双向链表是否为空 LOS_ListEmpty 判断链表是否为空
删除节点并初始化链表 LOS_ListDelInit 将指定的节点从链表中删除使用该节点初始化链表
在链表尾部插入链表 LOS_ListTailInsertList 将链表插入到双向链表尾部
在链表头部插入链表 LOS_ListHeadInsertList 将链表插入到双向链表头部其插入 | 删除 | 遍历操作是它最常用的社交三大件,若不理解透彻在分析源码过程中很容易卡壳。虽在网上能找到很多它的图,但怎么看都不是自己想要的,干脆重画了它的主要操作。
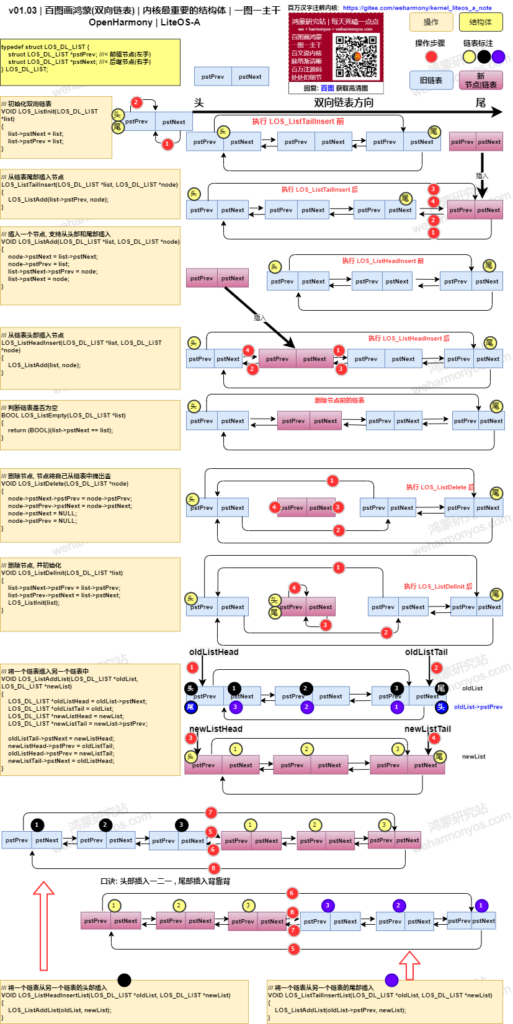
//将指定节点初始化为双向链表节点
LITE_OS_SEC_ALW_INLINE STATIC INLINE VOID LOS_ListInit(LOS_DL_LIST *list)
{
list->pstNext = list;
list->pstPrev = list;
}
//将指定节点挂到双向链表头部
LITE_OS_SEC_ALW_INLINE STATIC INLINE VOID LOS_ListAdd(LOS_DL_LIST *list, LOS_DL_LIST *node)
{
node->pstNext = list->pstNext;
node->pstPrev = list;
list->pstNext->pstPrev = node;
list->pstNext = node;
}
//将指定节点从链表中删除,自己把自己摘掉
LITE_OS_SEC_ALW_INLINE STATIC INLINE VOID LOS_ListDelete(LOS_DL_LIST *node)
{
node->pstNext->pstPrev = node->pstPrev;
node->pstPrev->pstNext = node->pstNext;
node->pstNext = NULL;
node->pstPrev = NULL;
}
//将指定节点从链表中删除,并使用该节点初始化链表
LITE_OS_SEC_ALW_INLINE STATIC INLINE VOID LOS_ListDelInit(LOS_DL_LIST *list)
{
list->pstNext->pstPrev = list->pstPrev;
list->pstPrev->pstNext = list->pstNext;
LOS_ListInit(list);
}数据在哪儿?
有好几个同学问数据在哪?确实LOS_DL_LIST这个结构看起来怪怪的,它竟没有数据域!所以看到这个结构的人第一反应就是我们怎么访问数据?其实LOS_DL_LIST不是拿来单独用的,它是寄生在内容结构体上的,谁用它谁就是它的数据。看图就明白了。
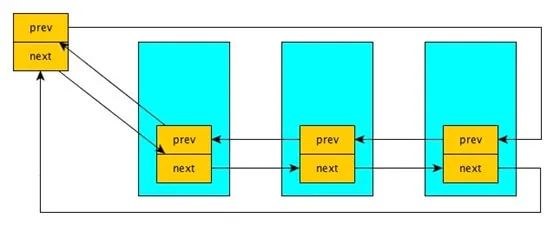
强大的宏?
除了内联函数,对双向链表的初始化,偏移定位,遍历 等等操作提供了更强大的宏支持。使内核以极其简洁高效的代码实现复杂逻辑的处理。
//定义一个节点并初始化为双向链表节点
#define LOS_DL_LIST_HEAD(list) LOS_DL_LIST list = { &(list), &(list) }
//获取指定结构体内的成员相对于结构体起始地址的偏移量
#define LOS_OFF_SET_OF(type, member) ((UINTPTR)&((type *)0)->member)
//获取包含链表的结构体地址,接口的第一个入参表示的是链表中的某个节点,第二个入参是要获取的结构体名称,第三个入参是链表在该结构体中的名称
#define LOS_DL_LIST_ENTRY(item, type, member) \
((type *)(VOID *)((CHAR *)(item) - LOS_OFF_SET_OF(type, member)))
//遍历双向链表
#define LOS_DL_LIST_FOR_EACH(item, list) \
for (item = (list)->pstNext; \
(item) != (list); \
item = (item)->pstNext)
//遍历指定双向链表,获取包含该链表节点的结构体地址,并存储包含当前节点的后继节点的结构体地址
#define LOS_DL_LIST_FOR_EACH_ENTRY_SAFE(item, next, list, type, member) \
for (item = LOS_DL_LIST_ENTRY((list)->pstNext, type, member), \
next = LOS_DL_LIST_ENTRY((item)->member.pstNext, type, member); \
&(item)->member != (list); \
item = next, next = LOS_DL_LIST_ENTRY((item)->member.pstNext, type, member))
//遍历指定双向链表,获取包含该链表节点的结构体地址
#define LOS_DL_LIST_FOR_EACH_ENTRY(item, list, type, member) \
for (item = LOS_DL_LIST_ENTRY((list)->pstNext, type, member); \
&(item)->member != (list); \
item = LOS_DL_LIST_ENTRY((item)->member.pstNext, type, member))LOS_OFF_SET_OF 和 LOS_DL_LIST_ENTRY
这里要重点说下 LOS_OFF_SET_OF和LOS_DL_LIST_ENTRY两个宏,个人认为它们是链表操作中最关键,最重要的宏。在读内核源码的过程会发现LOS_DL_LIST_ENTRY高频的出现,它们解决了通过结构体的任意一个成员变量来找到结构体的入口地址。这个意义重大,因为在运行过程中,往往只能提供成员变量的地址,那它是如何做到通过个人找到组织的呢?
LOS_OFF_SET_OF 用于找到成员变量在结构体中的相对偏移位置, 在系列篇 (用栈方式篇) 中 已说过,开源鸿蒙采用的是递减满栈的方式。而使用 ((type *)0)->member 是获取 struct 成员偏移量的技巧,需要编译器的支持,这种方法背后的想法是让编译器假设结构起始地址位于零并计算成员的地址。以ProcessCB 结构体举例:
typedef struct ProcessCB {
// ...
LOS_DL_LIST pendList; /**< Block list to which the process belongs | 进程所在的阻塞列表,进程因阻塞挂入相应的链表.*/
LOS_DL_LIST childrenList; /**< Children process list | 孩子进程都挂到这里,形成双循环链表*/
LOS_DL_LIST exitChildList; /**< Exit children process list | 要退出的孩子进程链表,白发人要送黑发人.*/
LOS_DL_LIST siblingList; /**< Linkage in parent's children list | 兄弟进程链表, 56个民族是一家,来自同一个父进程.*/
LOS_DL_LIST subordinateGroupList; /**< Linkage in group list | 进程组员链表*/
LOS_DL_LIST threadSiblingList; /**< List of threads under this process | 进程的线程(任务)列表 */
LOS_DL_LIST waitList; /**< The process holds the waitLits to support wait/waitpid | 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息*/
} LosProcessCB;waitList因为在结构体的后面,所以它内存地址会比在前面的pendList高,有了顺序方向就很容易得到ProcessCB的第一个变量的地址。LOS_OFF_SET_OF就是干这个的,含义就是相对第一个变量地址,你waitList偏移了多少。
如此,当外面只提供waitList的地址再减去偏移地址 就可以得到ProcessCB的起始地址。
#define LOS_DL_LIST_ENTRY(item, type, member) \
((type *)(VOID *)((CHAR *)(item) - LOS_OFF_SET_OF(type, member)))
当然如果提供pendList或exitChildList的地址道理一样。LOS_DL_LIST_ENTRY实现了通过任意成员变量来获取ProcessCB的起始地址。
OsGetTopTask
有了以上对链表操作的宏,可以使得代码变得简洁易懂,例如在调度算法中获取当前最高优先级的任务时,就需要遍历整个进程和其任务的就绪列表。LOS_DL_LIST_FOR_EACH_ENTRY高效的解决了层层循环的问题。
LITE_OS_SEC_TEXT_MINOR LosTaskCB *OsGetTopTask(VOID)
{
UINT32 priority, processPriority;
UINT32 bitmap;
UINT32 processBitmap;
LosTaskCB *newTask = NULL;
#if (LOSCFG_KERNEL_SMP == YES)
UINT32 cpuid = ArchCurrCpuid();
#endif
LosProcessCB *processCB = NULL;
processBitmap = g_priQueueBitmap;
while (processBitmap) {
processPriority = CLZ(processBitmap);
LOS_DL_LIST_FOR_EACH_ENTRY(processCB, &g_priQueueList[processPriority], LosProcessCB, pendList) {
bitmap = processCB->threadScheduleMap;
while (bitmap) {
priority = CLZ(bitmap);
LOS_DL_LIST_FOR_EACH_ENTRY(newTask, &processCB->threadPriQueueList[priority], LosTaskCB, pendList) {
#if (LOSCFG_KERNEL_SMP == YES)
if (newTask->cpuAffiMask & (1U << cpuid)) {
#endif
newTask->taskStatus &= ~OS_TASK_STATUS_READY;
OsPriQueueDequeue(processCB->threadPriQueueList,
&processCB->threadScheduleMap,
&newTask->pendList);
OsDequeEmptySchedMap(processCB);
goto OUT;
#if (LOSCFG_KERNEL_SMP == YES)
}
#endif
}
bitmap &= ~(1U << (OS_PRIORITY_QUEUE_NUM - priority - 1));
}
}
processBitmap &= ~(1U << (OS_PRIORITY_QUEUE_NUM - processPriority - 1));
}
OUT:
return newTask;
}结构的最爱
LOS_DL_LIST是复杂结构体的最爱,再以 ProcessCB(进程控制块)举例,它是描述一个进程的所有信息,其中用到了 7个双向链表,这简直比章鱼还牛逼,章鱼也才四双触手,但进程有7双(14只)触手。
typedef struct ProcessCB {
LOS_DL_LIST pendList; /**< Block list to which the process belongs | 进程所在的阻塞列表,进程因阻塞挂入相应的链表.*/
LOS_DL_LIST childrenList; /**< Children process list | 孩子进程都挂到这里,形成双循环链表*/
LOS_DL_LIST exitChildList; /**< Exit children process list | 要退出的孩子进程链表,白发人要送黑发人.*/
LOS_DL_LIST siblingList; /**< Linkage in parent's children list | 兄弟进程链表, 56个民族是一家,来自同一个父进程.*/
LOS_DL_LIST subordinateGroupList; /**< Linkage in group list | 进程组员链表*/
LOS_DL_LIST threadSiblingList; /**< List of threads under this process | 进程的线程(任务)列表 */
LOS_DL_LIST waitList; /**< The process holds the waitLits to support wait/waitpid | 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息*/
} LosProcessCB;解读:
pendList 个人认为它是开源鸿蒙内核功能最多的一个链表,它远不止字面意思阻塞链表这么简单,只有深入解读源码后才能体会它真的是太会来事了,一般把它理解为阻塞链表就行。上面挂的是处于阻塞状态的进程。
childrenList孩子链表,所有由它fork出来的进程都挂到这个链表上。上面的孩子进程在死亡前会将自己从上面摘出去,转而挂到exitChildList链表上。
exitChildList退出孩子链表,进入死亡程序的进程要挂到这个链表上,一个进程的死亡是件挺麻烦的事,进程池的数量有限,需要及时回收进程资源,但家族管理关系复杂,要去很多地方消除痕迹。尤其还有其他进程在看你笑话,等你死亡(wait/waitpid)了通知它们一声。
siblingList兄弟链表,和你同一个父亲的进程都挂到了这个链表上。
subordinateGroupList 朋友圈链表,里面是因为兴趣爱好(进程组)而挂在一起的进程,它们可以不是一个父亲,不是一个祖父,但一定是同一个老祖宗(用户态和内核态根进程)。
threadSiblingList线程链表,上面挂的是进程ID都是这个进程的线程(任务),进程和线程的关系是1:N的关系,一个线程只能属于一个进程。这里要注意任务在其生命周期中是不能改所属进程的。
waitList 是等待子进程消亡的任务链表,注意上面挂的是任务。任务是通过系统调用。
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);将任务挂到waitList上。开源鸿蒙waitpid系统调用为SysWait,具体看进程回收篇。
双向链表是内核最重要的结构体,精读内核的路上它会反复的映入你的眼帘,理解它是理解内核运作的关键所在!
百文说内核 | 抓住主脉络
子曰:“诗三百,一言以蔽之,曰‘思无邪’。”——《论语》:为政篇。
百文相当于摸出内核的肌肉和器官系统,让人开始丰满有立体感,因是直接从注释源码起步,在开源鸿蒙内核源码加注释过程中,每每有心得处就整理,慢慢形成了以下文章。内容立足源码,常以生活场景打比方尽可能多的将内核知识点置入某种场景,具有画面感,容易理解记忆。说别人能听得懂的话很重要! 百篇博客绝不是百度教条式的在说一堆诘屈聱牙的概念,那没什么意思。更希望让内核变得栩栩如生,倍感亲切.确实有难度,自不量力,但已经出发,回头已是不可能的了。
百万汉字注解内核目的是要看清楚其毛细血管,细胞结构,等于在拿放大镜看内核。内核并不神秘,带着问题去源码中找答案是很容易上瘾的,你会发现很多文章对一些问题的解读是错误的,或者说不深刻难以自圆其说,你会慢慢形成自己新的解读,而新的解读又会碰到新的问题,如此层层递进,滚滚向前,拿着放大镜根本不愿意放手。
与代码有bug需不断debug一样,文章和注解内容会存在不少错漏之处,请多包涵,但会反复修正,持续更新,v**.xx 代表文章序号和修改的次数,精雕细琢,言简意赅,力求打造精品内容。百篇博客系列思维导图结构如下:

根据上图的思维导图,我们未来将要和大家一一分享以上大部分关键技术点的博客文章。
百万汉字注解.精读内核源码
如果大家觉得看文章不过瘾,想直接撸代码的话,可以去下面四大码仓围观同步注释内核源码:
gitee仓:
https://gitee.com/weharmony/kernel_liteos_a_note
github仓 :
https://github.com/kuangyufei/kernel_liteos_a_note
codechina仓:
https://codechina.csdn.net/kuangyufei/kernel_liteos_a_note
coding仓:
https://weharmony.coding.net/public/harmony/kernel_liteos_a_note/git/files
写在最后
我们最近正带着大家玩嗨OpenHarmony。如果你有用OpenHarmony开发的好玩的东东,或者有对OpenHarmony的深度技术剖析,想通过我们平台让更多的小伙伴知道和分享的,欢迎投稿,让我们一起嗨起来!有点子,有想法,有Demo,立刻联系我们:
合作邮箱:zzliang@atomsource.org