开源鸿蒙内核源码分析系列 | 红黑树 | 众里寻他千百度(转载)
原文来自鸿蒙研究站:http://weharmonyos.com/blog/05.html
鸿蒙研究站网址:http://weharmonyos.com

二叉查找树 | BST
要理解红黑树,需要从二叉查找树(Binary Search Tree)开始说起。其特点是:
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。
例如:想要找到下图节点 10 就需要经过路径 [ 9 | 13 | 11 ]
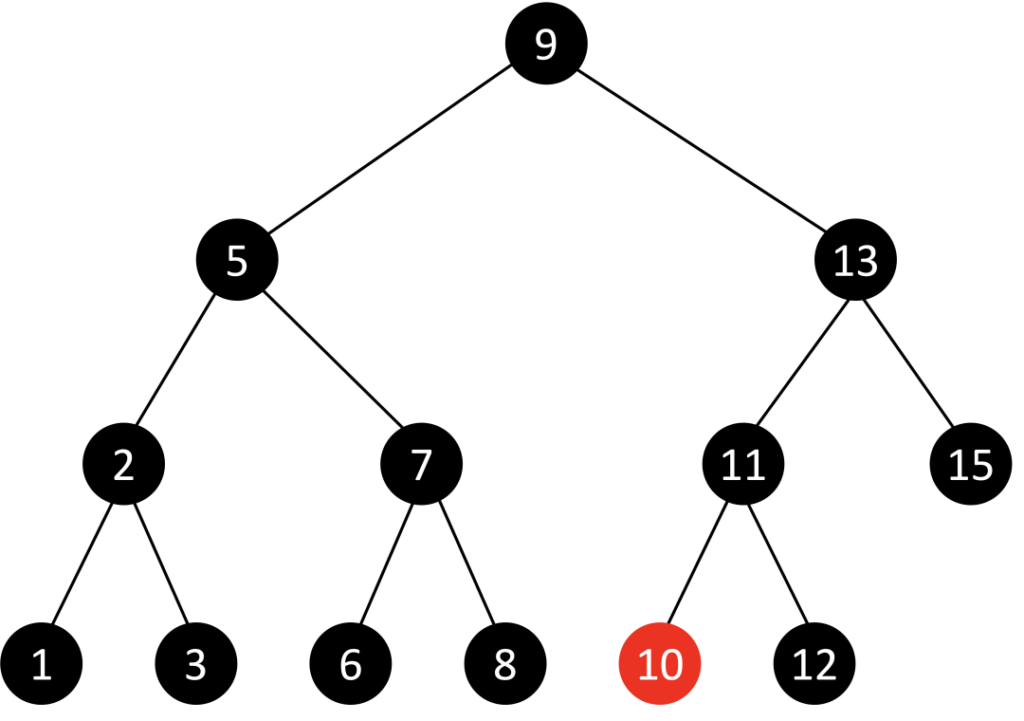
在理想的情况下,二叉查找树增删查改的时间复杂度为O(logN)(其中N为节点数),最坏的情况下为O(N)。
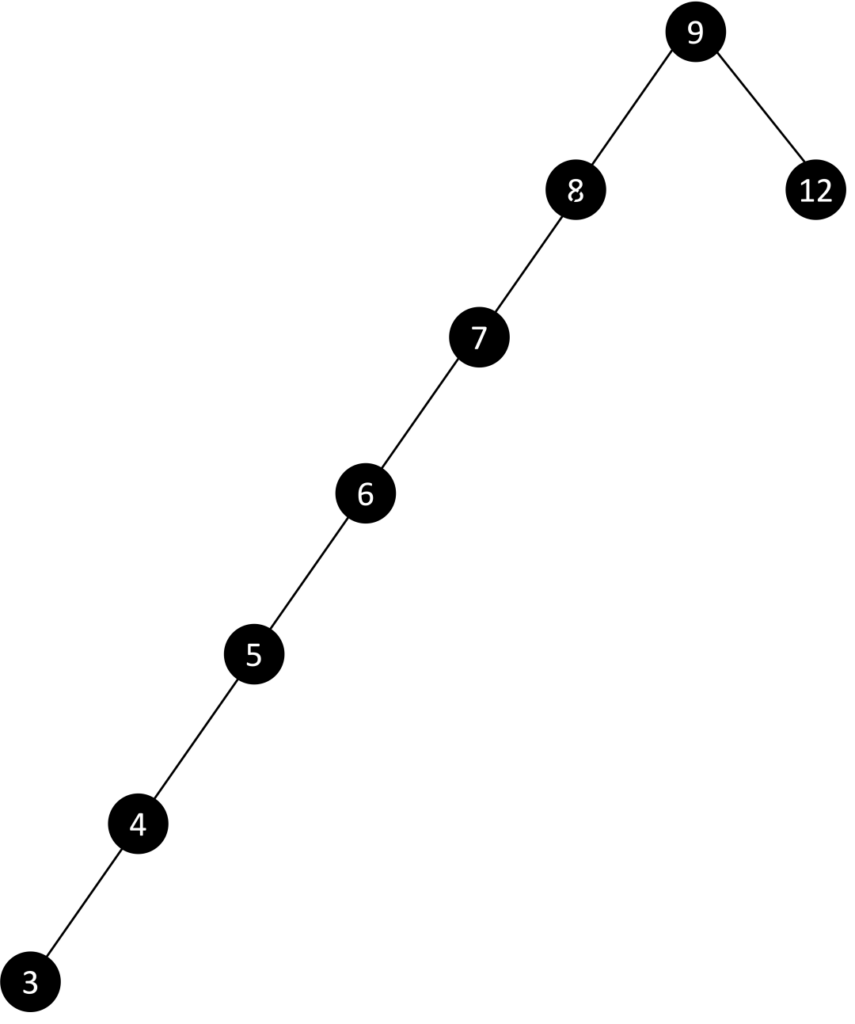
但 BST 的特点是在操作过程中容易失去平衡,数在插入的时候会导致树倾斜,不同的插入顺序会导致树的高度不一样,而树的高度直接的影响了树的查找效率。理想的高度是logN,最坏的情况是所有的节点都在一条斜线上,这样的树的高度为N。例如:下图为初始的二叉查找树:

接下来依次插入如下五个结点:7,6,5,4,3,结果将变成简直没法看的:
红黑树
基于BST存在的问题,一种新的树——平衡二叉查找树即 红黑树(Red-Black Tree,以下简称RBTree),它在插入和删除的时候,会通过旋转操作将高度保持在logN。通俗的讲就是会自我纠正,跟人睡觉一样,将自己的身体调整到一个让最省力,最舒服的姿势。其实际应用非常广泛,比如Linux内核中的完全公平调度器、高精度计时器、ext3文件系统等等,开源鸿蒙内核中也使用了红黑树来管理进程线性区。上图经过红黑树调整之后的姿势为:
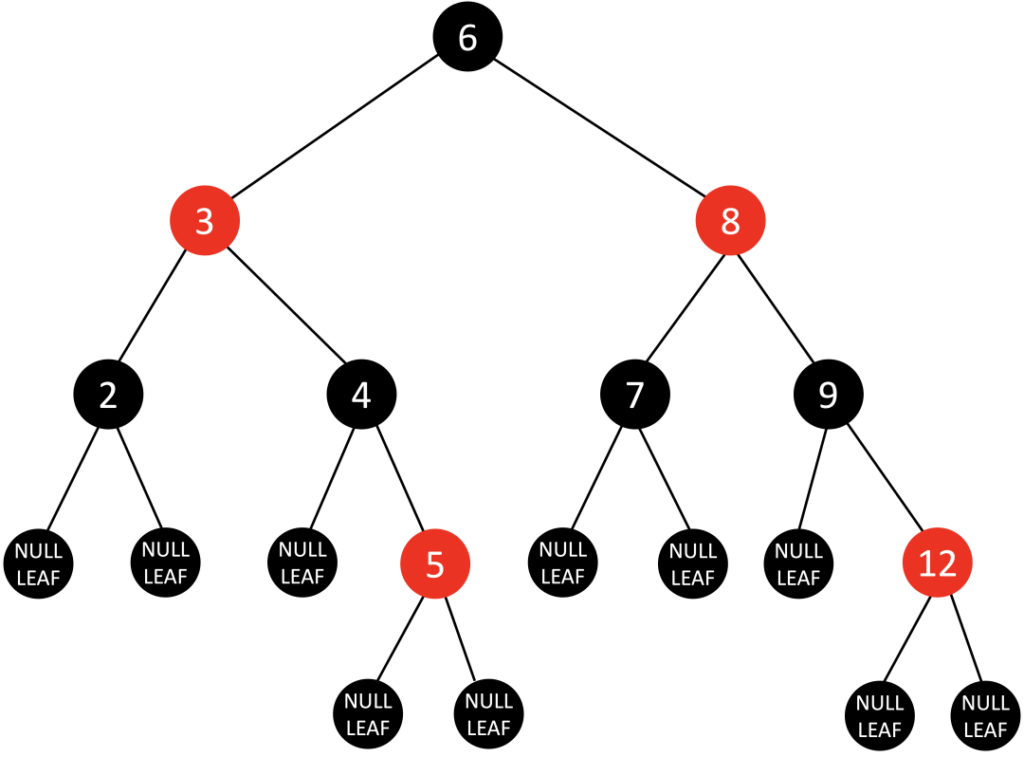
红黑树有以下几个特点:
1.任何一个节点都有颜色,黑色或者红色。
2.根节点是黑色的。
3.父子节点之间不能出现两个连续的红节点。
4.任何一个节点向下遍历到其子孙的叶子节点,所经过的黑节点个数必须相等。
5.空节点被认为是黑色的。
6.从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。
红黑树具体的调整姿势的方法有两种:
- 变色 根据红黑树的规则,尝试把红色结点变为黑色,或者把黑色结点变为红色。
- 旋转,根据旋转方向又分成 左旋转 和 右旋转左旋转(逆时针旋转) 红黑树的两个结点,使得父结点被自己的右孩子取代,而自己成为自己的左孩子。
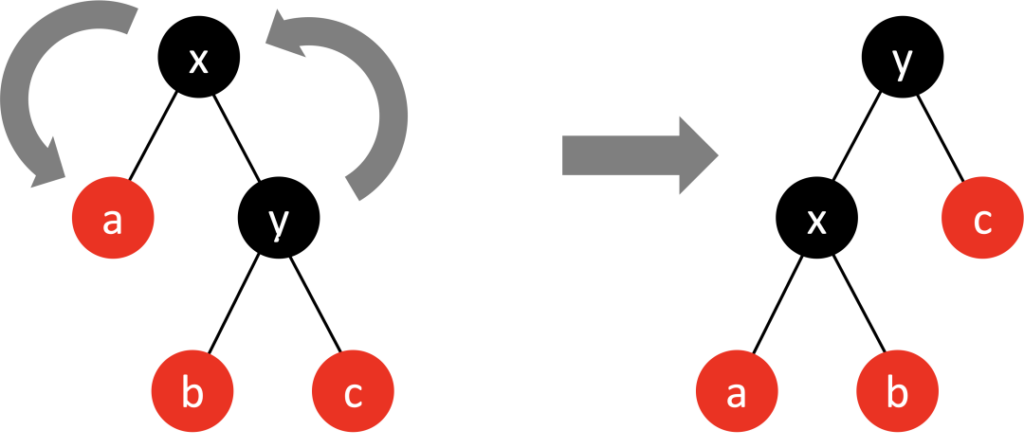
右旋转(顺时针旋转) 红黑树的两个结点,使得父结点被自己的左孩子取代,而自己成为自己的右孩子。
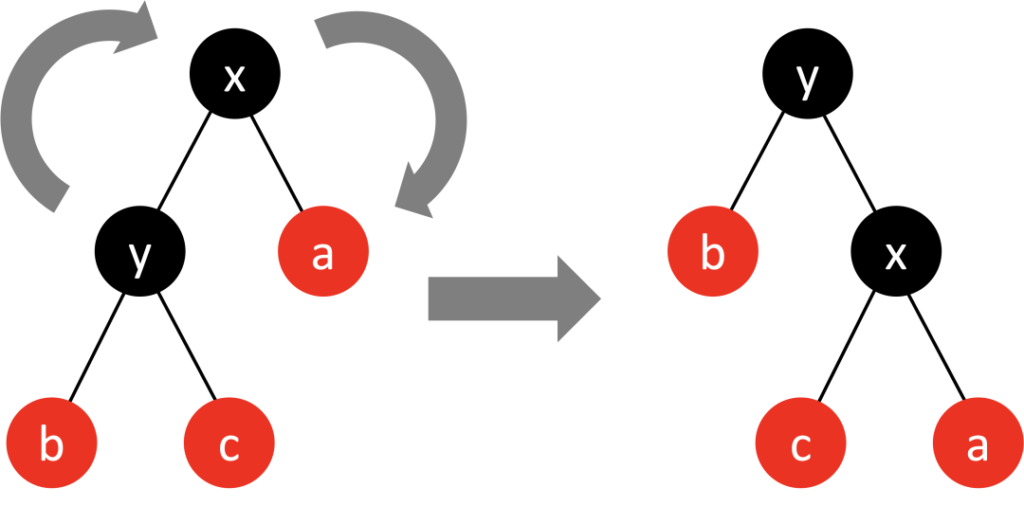
有兴趣的可以前往 红黑树演示网站(http://rbtree.phpisfuture.com/)玩一下,很有意思。
在开源鸿蒙使用?
开源鸿蒙使用红黑树主要用来管理进程的 线性区 ,关于线性区不清楚的请自行翻看系列篇,简单说就是一个虚拟地址连续的内存记录。我们动态申请堆内存其实就是申请了一个线性区,释放内存时就需要查找这个记录,这种使用频率很高,而红黑树的查找效率最高。开源鸿蒙红黑树功能的核心结构体是 LosRbTree ,每一个进程都有一颗属于自己的红黑树。
typedef struct VmMapRange {//线性区范围结构体
VADDR_T base; /**< vm region base addr | 线性区基地址*/
UINT32 size; /**< vm region size | 线性区大小*/
} LosVmMapRange;
typedef struct TagRbNode {//节点
struct TagRbNode *pstParent; ///< 爸爸是谁 ?
struct TagRbNode *pstRight; ///< 右孩子是谁 ?
struct TagRbNode *pstLeft; ///< 左孩子是谁 ?
ULONG_T lColor; //是红还是黑节点
} LosRbNode;
typedef struct TagRbTree {//红黑树控制块
LosRbNode *pstRoot;//根节点
LosRbNode stNilT;//叶子节点
LOS_DL_LIST stWalkHead;
ULONG_T ulNodes;
pfRBCmpKeyFn pfCmpKey; //比较两个节点大小 处理函数
pfRBFreeFn pfFree; //释放结点占用内存函数
pfRBGetKeyFn pfGetKey;//获取指定线性区范围 VmMapRange 函数
} LosRbTree;解读:
红黑树初始化,在进程空间初始化期间会初始化红黑树,并指定三个回调函数(方便红黑树节点的遍历)。
//初始化进程的红黑树
VOID LOS_RbInitTree(LosRbTree *pstTree, pfRBCmpKeyFn pfCmpKey, pfRBFreeFn pfFree, pfRBGetKeyFn pfGetKey)
{
OsRbInitTree(pstTree);
pstTree->pfCmpKey = pfCmpKey;
pstTree->pfFree = pfFree;
pstTree->pfGetKey = pfGetKey;
return;
}
//初始化进程虚拟空间
STATIC BOOL OsVmSpaceInitCommon(LosVmSpace *vmSpace, VADDR_T *virtTtb){
//...
LOS_RbInitTree(&vmSpace->regionRbTree, OsRegionRbCmpKeyFn, OsRegionRbFreeFn, OsRegionRbGetKeyFn);
}
///通过红黑树节点找到对应的线性区
VOID *OsRegionRbGetKeyFn(LosRbNode *pstNode)
{
LosVmMapRegion *region = (LosVmMapRegion *)LOS_DL_LIST_ENTRY(pstNode, LosVmMapRegion, rbNode);
return (VOID *)®ion->range;
}
///比较两个红黑树节点
ULONG_T OsRegionRbCmpKeyFn(const VOID *pNodeKeyA, const VOID *pNodeKeyB)
{
LosVmMapRange rangeA = *(LosVmMapRange *)pNodeKeyA;
LosVmMapRange rangeB = *(LosVmMapRange *)pNodeKeyB;
UINT32 startA = rangeA.base;
UINT32 endA = rangeA.base + rangeA.size - 1;
UINT32 startB = rangeB.base;
UINT32 endB = rangeB.base + rangeB.size - 1;
if (startA > endB) {// A基地址大于B的结束地址
return RB_BIGGER; //说明线性区A更大,在右边
} else if (startA >= startB) {
if (endA <= endB) {
return RB_EQUAL; //相等,说明 A在B中
} else {
return RB_BIGGER; //说明 A的结束地址更大
}
} else if (startA <= startB) { //A基地址小于等于B的基地址
if (endA >= endB) {
return RB_EQUAL; //相等 说明 B在A中
} else {
return RB_SMALLER;//说明A的结束地址更小
}
} else if (endA < startB) {//A结束地址小于B的开始地址
return RB_SMALLER;//说明A在
}
return RB_EQUAL;
}
插入结点,注意线性区结构体(VmMapRegion)的首个成员便是红黑树节点,对于红黑树来说线性区只是一个红黑树节点。
struct VmMapRegion {
LosRbNode rbNode; /**< region red-black tree node | 红黑树节点,通过它将本线性区挂在VmSpace.regionRbTree*/
// ...
}
//插入线性区,指的是向进程的红黑树 `LosRbTree` 插入 `LosRbNode`
BOOL OsInsertRegion(LosRbTree *regionRbTree, LosVmMapRegion *region)
{
if (LOS_RbAddNode(regionRbTree, (LosRbNode *)region) == FALSE) {
VM_ERR("insert region failed, base: %#x, size: %#x", region->range.base, region->range.size);
OsDumpAspace(region->space);
return FALSE;
}
return TRUE;
}具体插入过程不去说明,已经是很成熟的算法,通过比较线性区的范围来决定是插入进具体位置,插入过程会涉及到红黑树 颜色翻转 和 左右旋转 两种变化。
百文说内核 | 抓住主脉络
子曰:“诗三百,一言以蔽之,曰‘思无邪’。”——《论语》:为政篇。
百文相当于摸出内核的肌肉和器官系统,让人开始丰满有立体感,因是直接从注释源码起步,在开源鸿蒙内核源码加注释过程中,每每有心得处就整理,慢慢形成了以下文章。内容立足源码,常以生活场景打比方尽可能多的将内核知识点置入某种场景,具有画面感,容易理解记忆。说别人能听得懂的话很重要! 百篇博客绝不是百度教条式的在说一堆诘屈聱牙的概念,那没什么意思。更希望让内核变得栩栩如生,倍感亲切.确实有难度,自不量力,但已经出发,回头已是不可能的了。
百万汉字注解内核目的是要看清楚其毛细血管,细胞结构,等于在拿放大镜看内核。内核并不神秘,带着问题去源码中找答案是很容易上瘾的,你会发现很多文章对一些问题的解读是错误的,或者说不深刻难以自圆其说,你会慢慢形成自己新的解读,而新的解读又会碰到新的问题,如此层层递进,滚滚向前,拿着放大镜根本不愿意放手。
与代码有bug需不断debug一样,文章和注解内容会存在不少错漏之处,请多包涵,但会反复修正,持续更新,v**.xx 代表文章序号和修改的次数,精雕细琢,言简意赅,力求打造精品内容。百篇博客系列思维导图结构如下:

根据上图的思维导图,我们未来将要和大家一一分享以上大部分关键技术点的博客文章。
百万汉字注解.精读内核源码
如果大家觉得看文章不过瘾,想直接撸代码的话,可以去下面四大码仓围观同步注释内核源码:
gitee仓:
https://gitee.com/weharmony/kernel_liteos_a_note
github仓 :
https://github.com/kuangyufei/kernel_liteos_a_note
codechina仓:
https://codechina.csdn.net/kuangyufei/kernel_liteos_a_note
coding仓:
https://weharmony.coding.net/public/harmony/kernel_liteos_a_note/git/files
写在最后
我们最近正带着大家玩嗨OpenHarmony。如果你有用OpenHarmony开发的好玩的东东,或者有对OpenHarmony的深度技术剖析,想通过我们平台让更多的小伙伴知道和分享的,欢迎投稿,让我们一起嗨起来!有点子,有想法,有Demo,立刻联系我们:
合作邮箱:zzliang@atomsource.org