超节点算力革命(二)| 架构迭代、路径分化与核心要素解析
2026-01-20
以下文章来源于微信公众号——全球计算联盟GCC
【前文回顾】万亿参数大模型的训练与推理任务,对算力规模提出了革命性挑战,传统数据中心架构在通信效率与横向扩展能力上已难以适配。在此背景下,集成计算、网络、存储与散热于一体的机柜级超高密度计算单元——“超节点”,成为新一代AI算力基础设施的核心范式。其通过高速互联技术,将数十至上千个
GPU/NPU等计算芯片深度耦合,构建为高带宽、低延迟的大规模计算单元,从根本上突破了大规模并行任务中的协同效率瓶颈。
超节点历经从借鉴高性能计算集群、GPU/NPU密集化部署,到“原生超节点”全栈协同设计的不同阶段迭代。全球产业呈现技术路线与生态战略分化的多元格局:NVIDIA以极致性能领跑,AMD以开放生态构建差异化优势;国内企业加速自主创新,华为、阿里云、海光/ 中科曙光等推出系列创新产品,在高端计算领域展现出强劲的追赶超越潜力。超节点不仅是技术架构的迭代升级,更是全球科技竞争的战略制高点,其发展水平直接决定了国家在人工智能、科学计算、数字经济等关键领域的核心竞争力,成为推动科技自立自强与产业数字化转型的核心支撑。
超节点发展历程:
从集群协同到超节点架构
超节点的诞生是计算架构适应复杂计算任务数十年演进的必然结果,其发展脉络呈现为三个关键阶段。
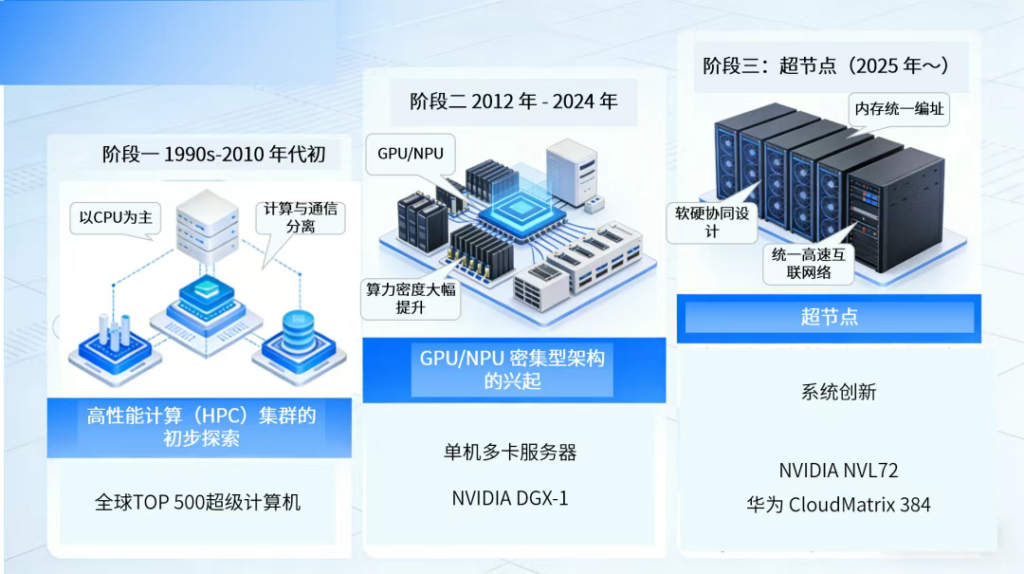
阶段一:高性能计算(HPC)集群的初步探索(1990s-2010 年代初)
AI浪潮兴起前,大规模并行计算需求集中于科学计算与工程模拟领域。早期 HPC集群以成千上万个CPU服务器节点为核心,通RDMA网络(InfiniBand/RoCE)等高速网络连接,基于MPI编程模型实现协同计算,核心逻辑是“横向扩展(Scale-Out)”,即通过增加节点数量提升总算力,适用于物理模拟、气候预测等场景。
1、技术特征:以CPU为核心计算单元;节点间通过松散网络连接,通信延迟达毫秒级;计算与通信分离,通信开销成为扩展性瓶颈。
2、代表性实践:全球TOP500超级计算机,虽性能强劲,但架构难以适配深度学习所需的高强度、低时延数据交换模式。
3、产业启示:积累了大规模节点互联、并行计算模型、系统管理及散热等技术经验,验证了多计算单元协同解决复杂问题的可行性,奠定了超节点的思想基础。
阶段二:GPU/NPU 密集型架构的兴起(2012 年 – 2024 年)
AlexNet的革命性突破释放了深度学习潜力,GPU作为并行计算利器在人工智能领域快速普及,架构重心转向利用大量GPU/NPU与高效联接。
1、技术特征:形成“节点内PCIe/NVLink+节点间RoCE/InfiniBand”两级互联架构;算力密度大幅提升,但跨节点通信延迟与拓扑复杂性仍是挑战;本质为仍为“服务器集群”,编程与调度需显式管理两级网络,复杂度较高。
2、技术里程碑:
①单机多卡服务器:计算单元从单CPU服务器演进为4卡、8卡乃至16卡 GPU/NPU服务器,内部通过PCIe Switch 或NVLink实现高速通信,典型代表为NVIDIA DGX-1(搭载8块NVIDIA Tesla V100 GPU)。
②“Pod”/ 集群概念:数十台至百台AI服务器通过InfiniBand/RoCE等高速网络连接形成计算“Pod”,NVIDIA DGX Pod、Google TPU Pod为典型代表。
③Scale-Out 专用网络:以RDMA网络(IB/RoCE)为核心的横向扩展网络技术,解决节点间通信问题。
3、产业启示:随着模型参数从数亿增至万亿级,单节点服务器不足以承载大模型,跨节点通信延迟与带宽远逊于节点内GPU互联,催生了算力更集中、内部通信更高效的超节点架构。
阶段三:超节点,全栈协同与生态化发展(2025 年~)
为支撑万亿参数巨型模型训练、推理,AI集群规模需扩展至数千乃至十万个GPU,传统两级互联架构瓶颈凸显,超节点应运而生。其核心理念是将整个机柜甚至多机柜的计算、存储、网络资源,从设计之初视为单一内聚的计算系统。
1、核心转变:从“硬件堆叠”转向“系统创新”,从“连接服务器”转向“构建计算单元”。
2、技术特征:
统一高速互联网络:采用NVLink、华为UB“灵衢”、Google ICI等技术,构建单层或扁平化全对全连接网络,实现纳秒级低延迟通信。
内存统一编址:支持GPU直接访问其他GPU内存,无需CPU中转,简化并行编程模型,提升数据共享效率。
软硬协同设计:硬件架构、通信库、编译器、调度系统协同优化,软件可感知拓扑结构并智能调度任务与数据流。
系统级可靠性:内置故障检测、隔离与恢复机制,保障万卡规模训练任务持续高可靠运行。
3、技术里程碑:NVIDIA NVL72、华为CloudMatrix 384、Google TPU v7p SuperPod,标志着超节点技术成熟;“机柜即计算机”理念落地,单机柜从8卡向72卡、384卡乃至上千卡演进;全栈协同设计成为主流,涵盖计算、网络、存储、供电、散热及软件生态的全方位优化。
全球超节点技术路径
超节点市场竞争已从单一芯片性能比拼,演变为系统架构、互联技术、软件生态及能源效率的全方位博弈,创新层出不穷,形成国际引领与国内追赶并行的格局。按协议开放性与生态模式分类,分化为垂直整合与开放架构两大技术路径。
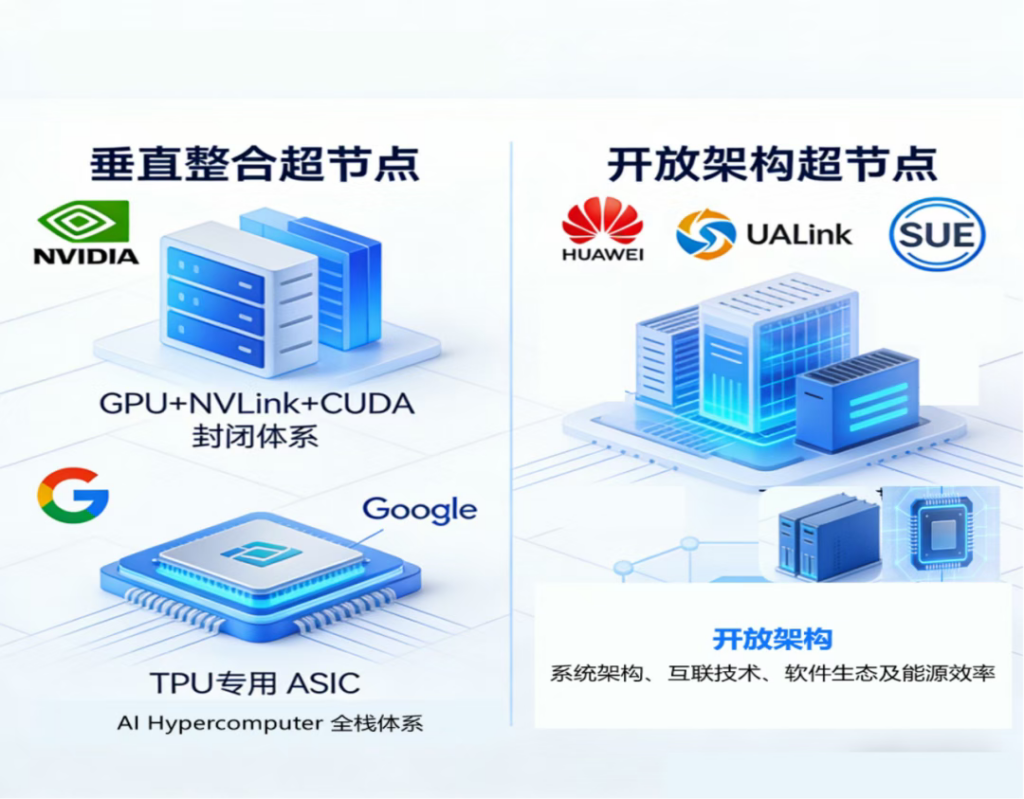
(一)垂直整合路径,全栈闭环构建技术壁垒
基于其自研的、不公开或部分公开的专用互联协议、硬件接口和软件栈构建的超节点方案。垂直整合模式的核心是实现从芯片、互联、硬件集成到软件生态的全链条自研,通过软硬件深度协同构建高壁垒竞争优势,但存在供应商锁定风险,生态相对封闭,代表企业为NVIDIA和谷歌为代表。
1、NVIDIA英伟达(标杆):2025年大规模部署的NVL72系统成为超节点技术标杆,构建了“GPU+NVLink+CUDA”垂直整合封闭体系。其单机柜集成36个Grace CPU与72个Blackwell B200 GPU,FP4 Tensor Core训练算力达1.4 ExaFLOPS,支持多精度算力适配;通过第五代 NVLink 实现130TB/s 全对全互联带宽,纳秒级延迟突破“通信墙”;配备HBM3e与LPDDR5X内存,整柜峰值功耗130-140kW,依赖液冷技术实现散热。生态层面,通过CUDA、cuDNN等软件工具链绑定全球AI开发者,面向大型云服务商提供“交钥匙”解决方案,占据高端 AI训练市场主导地位。未来将推出NVL144(2026 年,3.6 EFLOPS)、NVL576(2027 年,15 EFLOPS),持续巩固系统级算力优势。
2、Google谷歌:以自身业务与云端客户需求为核心,深度定制硬件架构与软件栈,实现软硬件极致协同。为内部业务(搜索、广告)与GCP客户设计专用ASIC芯片(TPU),构建AI Hypercomputer全栈体系。2025年发布的TPU v7(Ironwood)单芯片FP8算力4.6 PFLOPS,配备192GB HBM3e 内存,内存带宽7.3TB/s,强调能效比与推理性能;通过ICI网络将数千颗TPU组成“Superpod”,算力42.5 EFLOPS。商业模式采用“自产自销 + 云服务”,TPU不对外销售,通过GCP提供算力租赁服务,与TensorFlow、JAX框架深度协同,形成封闭但高效的生态,核心竞争力在于差异化云端算力服务与成本控制。
二)开放架构路径,通过“协议开放”模式,构建基于开放标准的、更加多元化的生态系统
基于开放标准或由开放产业联盟推动制定的互联协议与架构规范构建的超节点方案。旨在打破私有协议的垄断,实现不同厂商硬件(计算、网络、存储)的互操作性,降低用户总体拥有成本(TCO),激发产业创新。
1、华为(UB灵衢):从互联协议到基础软硬件全面开放的技术体系,构建昇腾超节点生态全栈解决方案。2025年发布的Atlas 900(CM384)超节点,由384颗昇腾910C NPU 组成,通过华为“灵衢”(UnifiedBus)互联协议实现全对全拓扑连接,BF16算力达300 PFLOPS(为同期NVL72 的3倍以上),总内存49.2TB、内存带宽1229TB/s。协议层通过开放互联总线灵衢UB协议,生态上以开源开放的CANN架构为核心,联合高校、科研机构与企业构建生态。CM384出货超300套,覆盖互联网及云服务商、电信运营商及科研机构。未来规划Atlas 950(2026Q4,8192卡,8 EFLOPS)、Atlas 960(2027Q4,15488 卡,30 EFLOPS),持续提升超大规模集群能力。
2、UALink:UALink(Ultra Accelerator Link)是2024年10月成立,核心使命是构建可扩展、高性能、低成本的AI加速器互联解决方案,打破专有互联技术的垄断壁垒。UALink阵营汇聚全球科技巨头,包括AMD、Intel、AWS、微软、Meta等创始成员,以及阿里云、苹果、新思科技等后续加入的董事会成员。其优势:一是性能,单通道速率达200GT/s,四通道配置双向带宽800Gbps,端到端时延低至235ns,较传统以太网提升4倍;二是生态开放,兼容现有以太网基础设施,支持多厂商加速器无缝互联,降低集成成本。预计基于UALink的超节点整机产品2026年推向市场。
3、SUE(Scale Up Ethernet 博通):是博通推出的AI纵向互联(Scale-up)技术框架,核心定位为构建多XPU系统间高速通信链路,适配超节点算力集群的规模化扩展需求,填补传统以太网在高密度算力协同场景的性能空白,为大模型训练等高频交互任务提供内存语义级通信支撑。其阵营以博通为核心,汇聚全球头部云服务与芯片设计企业,核心合作伙伴包括谷歌、Meta、OpenAI等终端需求方,阵营成员覆盖AI算力集群构建的各关键环节。业务模式以一站式芯片设计服务为核心,提供从架构定义、IP适配到流片封装的全流程定制服务。配套超节点整机系统预计2026年中上市。
4、ETH-X:由开放数据中心委员会(ODCC)主导、中国信通院与腾讯牵头设计的开放超节点技术体系,基于以太网技术构建,核心定位为通过Scale Up(纵向扩展)与Scale Out(横向扩展)协同组网,实现超节点内GPU集群高密度互联与跨集群规模化扩展,适配大模型训练与推理的高带宽、低时延算力需求。其阵营汇聚30余家产学研机构,形成全产业链协同生态:核心牵头方为腾讯,关键成员包括锐捷与中兴等设备商、燧原科技与壁仞科技等算卡提供商,以及立讯技术等高速互联方案商,覆盖超节点构建全环节。优势:跨卡数据访问时延降低12.7倍,支持8~512卡弹性组合;基于以太网实现开放兼容,降低集成成本。业务模式以开放标准为核心,通过产学研协同推进技术落地与产业化。超节点产品规模化上市时间预计为2026年。
超节点核心组成
超节点产业是技术密集、资本密集的复杂生态系统,产业链分为核心器件、高速互联网络、基础硬件层、软件生态层,各环节深度协同、相互赋能,共同决定超节点的算力性能与应用价值。
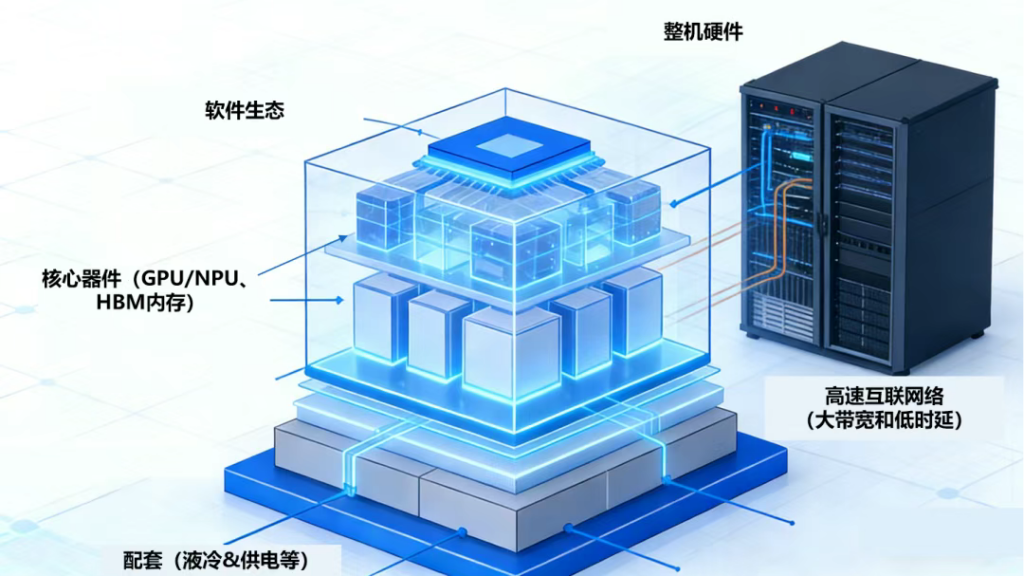
(一)核心器件
1、计算芯片:作为超节点“心脏”的AI加速器,包括GPU(NVIDIA主导,AMD追赶)、NPU(华为昇腾为代表)、TPU(Google自研,适配自身软件生态);CPU(IntelXeon、AMDEPYC、NVIDIAGrace、华为鲲鹏920等)负责资源调度,在超节点中,CPU常与加速器紧密耦合,提供协同计算能力。
2、HBM内存:HBM通过3D堆叠技术(8-16层DRAM芯片垂直堆叠)与硅通孔(TSV)、微凸块(Microbump)互联,实现颠覆性性能,突破超节点的”内存墙”,为GPU/TPU提供无阻塞数据供给,释放峰值算力;AI计算中数据搬运能耗占系统总功耗60%+,HBM大幅降低这一开销。代表企业:SK海力士(SKHynix)、三星(Samsung)、美光(Micron)。
(二)高速互联网络
高速互联网络是超节点实现大规模协同计算的核心纽带,分为节点内互联(Scale-Up)与节点间互联(Scale-Out)两个层面,共同构建高带宽、低延迟的通信体系。
1、节点内互联(Scale-Up): 主要用于连接同一超节点内的所有AI芯片。NVIDIA的NVLink、华为的UB灵衢等高速总线。其特点是超高带宽、超低延迟,是实现单机柜内全互联的关键。
2、节点间互联(Scale-Out): 用于连接多个超节点,构建更大规模的集群。传统上由InfiniBand和RoCE主导。灵衢2.0的雄心在于成为“统一总线”,旨在连接不同类型的计算单元,构建开放、可组合的算力底座,同时支持Scale-Up和Scale-Out两种扩展模式。
3、互联技术:主要有铜互联和光互联。铜缆互联,如DAC(无源铜缆)和AEC(有源铜缆),优势为低功耗、低成本、高可靠性,但传输距离短(DAC≤3米,AEC≤7米),限制超节点规模(如NVL72支持72卡)。光纤互联,如FDO、LPO、LRO、CPO,突破距离限制,支持更大规模(如CloudMatrix384支持384卡),但功耗、成本和故障率较高。代表企业:立讯精密、中际旭创、新易盛等。
4、交换网络:核心网络互连组件,由交换芯片模块、接口模块、控制模块等构成,承担数据路由、设备动态管理、性能优化等任务,本质是集成单颗或多颗交换芯片的交换机。代表企业:华为、思科、中兴通讯、新华三等。
(三)硬件整机及其配套
将芯片、内存、互联、散热、电源等组件整合为完整系统,核心玩家包括NVIDIA、华为、中科曙光等系统厂商,及超聚变、浪潮信息、新华三等服务器OEM/ODM厂商。
1、散热系统:液冷已成为超节点标配,分为冷板式(平衡成本与性能,适用于辅助组件)与浸没式(追求极致散热,适用于核心计算组件),直接决定算力密度、能效比与稳定性,支撑单机柜千瓦级功耗部署。冷却液分配单元(CDU):液冷系统的核心,负责冷却液的循环、温度控制和压力管理。
2、供电:超节点的供电设计已从传统分散式AC供电,转向以高压直流、集中管理为核心的高效可靠架构,以支撑AI算力基础设施的持续演进。
3、管理与监控硬件:机柜管理控制器(RMC)——在超节点机柜层级,由统一的RMC来管理整个机柜的电源、散热和环境状态。
(四)软件生态层:构建用户粘性的“护城河”
软件是释放硬件潜力的关键,也是厂商核心竞争力的核心,分为基础软件与平台软件两大层级,共同构建超节点的“灵魂”。
1、基础软件:作为连接硬件与上层应用的桥梁,包括计算架构/驱动(NVIDIACUDA、华为CANN、AMDROCm)、编译器等,是构建自主生态的核心。其中,驱动软件直接决定硬件兼容性与性能发挥,编译器通过优化计算图,深度发掘硬件性能潜力,是实现软硬协同的关键环节。
2、平台软件:操作系统、并行计算平台、AI框架(TensorFlow、PyTorch、MindSpore)、集群管理与调度系统、通信库等,定义超节点的核心功能。集群管理与调度系统负责资源分配、任务调度、故障处理,保障大规模集群稳定运行;AI框架作为开发者与超节点的交互接口,其生态成熟度直接决定超节点的易用性;通信库优化节点间与节点内的数据传输效率,进一步降低通信延迟。整体而言,软件生态的成熟度直接决定超节点的易用性与性能发挥,是构建用户粘性的“护城河”。
结语
超节点作为AI时代的“算力引擎”,正深刻重塑全球科技竞争格局。国际层面,NVIDIA凭借技术先发优势与CUDA生态壁垒保持领先,AMD、Google通过开放与自定义路径形成差异化竞争;国内层面,华为、阿里云、海光/曙光分别以垂直整合、云原生、开放生态为核心,在自主可控战略驱动下实现快速崛起。
更多超节点相关议题将在2026AIDC产业发展大会暨Open AI Infra Summit上迎来集中探讨与实践交流。无论你是技术研发人员、企业决策者还是科研工作者,都能在这里突破瓶颈、链接资源、预判趋势。现大会预报名通道已开启,展位与赞助席位已同步开放,欢迎扫描下方二维码进入预报名通道,共话下一代算力格局!
