河套 IT TALK 74:(原创)解读老黄与Ilya的炉边谈话系列之三——超越玄幻,背后是人类老师的艰辛付出(万字长文)

一个月前,就在GPT 4发布的第二天,同时也是英伟达(NVIDIA)线上大会的契机,英伟达的创始人兼CEO黄仁勋(”Jensen” Huang)与OpenAI的联合创始人兼首席科学家伊尔亚-苏茨克维(Ilya Sutskever )展开了一次信息量巨大的长达一个小时的“炉边谈话”(Fireside Chats)。期间谈到了从伊尔亚-苏茨克维早期介入神经网络、深度学习,基于压缩的无监督学习、强化学习、GPT的发展路径,以及对未来的展望。相信很多人都已经看过了这次谈话节目。我相信,因为其中掺杂的各种专业术语和未经展开的背景,使得无专业背景的同仁很难彻底消化理解他们谈话的内容。本系列尝试将他们完整的对话进行深度地解读,以便大家更好地理解ChatGPT到底给我们带来了什么样的变革。今天,就是这个系列的第三篇:超越玄幻,背后是人类老师的艰辛付出。

对话译文(03):
Ilya Sutskever:第二个想法,我认为现在是一个好时机,那就是强化学习(Reinforcement Learning)。
这显然也很重要。我们在 OpenAI 中完成的第一个真正的大型项目,是解决一个实时战略游戏。或者说,实时战略游戏就像是一项竞技运动,你需要聪明,你需要更快,你需要快速反应,有团队合作。你正在与另一个团队竞争,这是非常、非常复杂的。并且这个游戏有一个完整的竞争联赛,这个游戏叫做DOTA2。
因此,我们训练了一个强化学习 AI 代理来与自己对抗。目标是达到一定水平,以便可以与世界上最好的玩家竞争。这也是一个重大项目,它是一个非常不同的工作方向,就是强化学习。
黄仁勋:是的,我记得你们宣布这项工作。顺便说一句,当我早些时候问的时候,OpenAI 已经做了大量的工作,有些看起来像是走了弯路。但事实上,正如你现在解释的那样,它们可能是弯路,看起来像是弯路,但它们真正导致了我们现在讨论的ChatGPT 的一些重要工作。
Ilya Sutskever:是的,我的意思是,在GPT 产生基础的地方,已经有了真正的融合。从基于DOTA 的强化学习,变成了基于人类反馈的强化学习。这种组合带给了我们ChatGPT。
黄仁勋:这里有个误解,人们认为 ChatGPT 本身只是一个巨大的大型语言模型。但事实上,围绕着它的是一个相当复杂的系统。你能为观众简单解释一下吗?包括它的微调,它的强化学习,你知道是周围的各种系统才能让它运作起来,让它提供知识等等。
Ilya Sutskever:是的,我可以这样想,当我们训练一个大型神经网络来准确预测互联网上许多不同文本中的下一个词时,我们正在做的是,我们正在学习一个世界模型。看起来我们是在学习,表面上看起来我们只是在学习文本中的统计相关性。但实际上,只是去学习文本中的统计相关性,就可以把这些知识压缩得非常好。
神经网络所学习的是生成文本过程中的一些表述。这个文本实际上是这个世界的一个映射,世界在这些文字上映射出来。因此,神经网络正在学习从越来越多的角度去看待这个世界,看待人类和社会,看人们的希望、梦想和动机,以及相互之间的影响和所处的情境。神经网络学习一种压缩的、抽象的、可用的表示形式。这是从准确预测下一个词中学到的东西。
此外,你对下一个词的预测越准确,还原度越高,在这个过程中你得到的世界的清晰度就越高。这就是预训练阶段的作用。但是,这不能让神经网络表现出我们希望它能够表现出的行为。
你看一个语言模型,它真正要做的是回答以下问题。如果我在互联网上有一些随机的文本,它以一些前缀、一些提示开始,它将补全什么内容呢?可能只是随机地用互联网上的一些文本来补全它,这和我想拥有一个助手是不同的。一个真实的、有用的,遵循某些规则的助手,是需要额外训练的。这就是微调(Fine-tuning)和基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback),以及其他形式的 AI 辅助可以发挥作用的地方。
不仅仅是基于人类反馈的强化学习,也是基于人类和 AI合作的强化学习。人类老师与 AI 一起合作,去教导我们的 AI 模型。但不是教它新的知识,而是与它交流,向它传达我们希望它成为什么样子。
而这个过程,第二阶段,也是极其重要的。第二阶段做得越好,这个神经网络就越有用,越可靠。它不同于第一阶段,它尽可能多地从世界的映射中学习这个世界的知识,也就是文字。
黄仁勋:你可以对它进行微调,你可以指示它执行特定任务,那么你可不可以指示它别做一些事情?你给它设置一些安全护栏,去避免某一类型的行为。也就是说给它一些边界,这样它就不会偏离这个边界,去执行那些不安全的事情。
Ilya Sutskever:是的,所以第二阶段的训练确实是我们向神经网络传达我们想要的任何东西,其中就包括边界。我们做得越好,我们传达的这个边界的精确度就越高。因此,我们通过不断的研究和创新来提高这种精确度。我们确实能够提高这种精确度,从而使它在遵循预期指令的方式上变得越来越可靠和精确。
智愿君:让我们继续解读老黄和Ilya炉边谈话的第三段对话,信息量同样满满。上回,我们谈到了主要是无监督学习、情感神经元和大模型,那都是GPT一开始要做的事情。但要把GPT做的尽量完美,Ilya也提到了,就需要两个关键动作:微调(Fine-tuning)和基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)。接下来,我们会展开来谈这两个话题。
ChatGPT这么火热,很多人都崇拜AI本身,大谈特谈的是无监督学习,是炼丹师在大模型无监督学习的丹炉中九九八十一天的自我演化、自我觉醒,然后涌现了智慧之光的仙丹炼成,听起来玄幻,但是很多人喜欢听。但其实,如果把ChatGPT比作精致瓷器的话,那是经过无数工匠的手工打磨的。我说的不是OpenAI的大神们,而是今天要特别强调的,人工标注师和人工训练师们。这个基数有多少呢?至少百万起……
刻意被回避的有监督学习
在微调阶段和基于人类反馈的强化学习阶段,Ilya刻意淡化了有监督的执行细节。其实根据ChatGPT披露的信息,这两个阶段使用的都是有监督学习。具体来说,微调分为两个段,一个叫指令调整(Instruction Tuning),一个叫对齐调整(Alignment Tuning)。
指令调整
在指令调整阶段,ChatGPT使用1.5万个人工编写的问题-答案对来微调模型,以更好地适应特定的任务。这个阶段的目标是使模型更好地理解和回答问题。
指令调整(Instruction Tuning)将多种任务转化成自然语言表述的形式,再通过seq2seq的监督学习+多任务学习的方式调整大规模语言模型的参数。经验表明,指令调整可以让大模型更好地执行指令,并提高跨任务与跨语言的泛化能力,并且可以缓解大模型输出重复内容以及补全输入而非完成任务的问题。
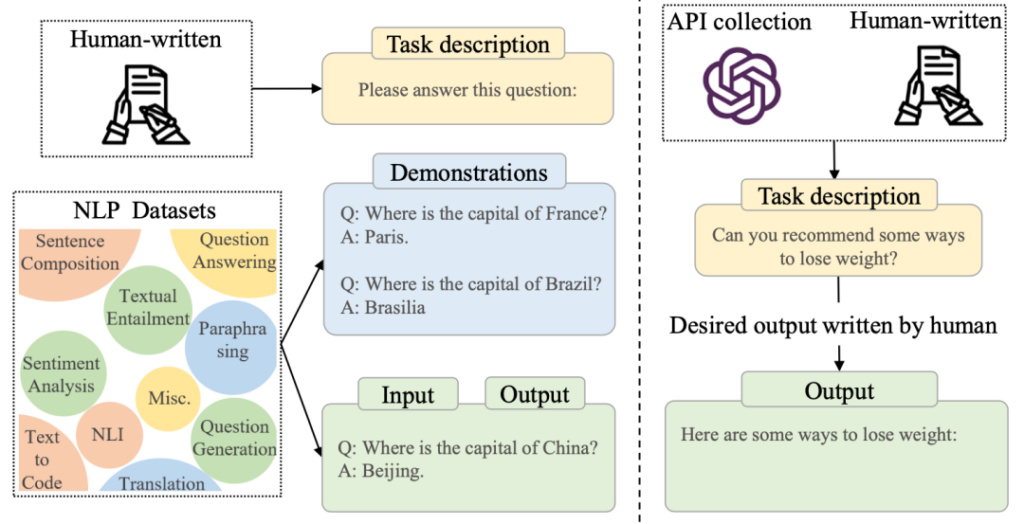
上图展示了指令精调的数据样例,通常包括一个任务描述,一组可选的展示样例,以及一组输入输出。模型在训练时,利用输出内容,进行监督学习训练。
指令调整的数据主要有两个来源:
- 第一个来源为上图左侧,根据现有的数据集进行改写构建。其中,主要涉及通过众包平台构建不同的任务描述,有些工作用启发式模板构建数据,还有工作提出通过颠倒输入输出的方式扩充数据。
- 第二个来源为上图右侧,基于人类需求构建指令调整数据。InstructGPT提出利用人类在OpenAI API中输入的数据作为任务描述,以提高指令的多样性,更好满足真实需求。过程中涉及收集用户query,让标注者再计一些query,让标注者写出query的回复作为训练目标。GPT-4还额外构建高风险query来让模型学习“拒绝回复”。第二类数据在后面的对齐调整中也用到了。
在指令调整过程中,任务的数量和多样性对跨任务泛化能力很重要。多样性可以体现在长度、结构、创造性等多个方面。而每个任务所需的样本无需过多。
对齐调整
除了上述的指令调整来提升建模语言完成特定任务外,对于ChatGPT这类“对话产品”而言,还需要通过对齐调整(Alignment Tuning)来让模型同人类的价值观对齐,从而生成“更令人满意”的回复内容。对齐调整的主要动机是,有害的、误导的和有偏见的表述会严重影响人们主观的评价。即使这种调整客观上会损害大模型的能力,但可以极大地提升用户体验。大体上有三个需要调整的方向:
- 有帮助的:模型生成的内容应当是简介有执行力的,能够提供额外的信息并展现出模型的敏感、审慎和洞察力。
- 忠诚的:模型不应该捏造事实,并且适当地时候表达不确定性。
- 无害的:模型避免生成冒犯的、歧视性的内容,并且拒绝一些恶意请求。
用于对齐调整的标注数据有多种形式,例如排序若干候选;成对比较;回答既定的问题以从多个角度评价等。GPT-4还利用了基于自身的零监督分类器。我们后续再逐步展开。
而在标注者质量筛选方面,除了母语、学历、标注平台(如AMT)上等级之外,研究者还利用标注者之间的内在一致性、标注者与研究者的标注一致性等信息来对标注者做筛选。
对齐调整阶段中也使用了监督学习。这个阶段的目的是通过让ChatGPT尝试根据上下文来生成问题或回答,然后再将这些生成的问题或回答与人工提供的标准问题或回答进行比较,以进一步提高ChatGPT的准确性和一致性。在这个过程中,使用的也是基于人类反馈的强化学习(RLHF)方法。我们下面再展开来讲。
基于人类反馈的强化学习(RLHF)
基于人类反馈的强化学习(RLHF)是一种利用人类反馈进行强化学习的方法。这里其实是两个关键词,第一个是强化学习,第二个是基于人类反馈。
强化学习是一种基于智能体在环境中与外部世界交互来学习决策的机器学习方法。在强化学习中,智能体通过尝试不同的动作来学习如何最大化某种奖励信号。强化学习通常被用于处理连续的状态和动作空间,并且具有一定程度的探索和利用平衡,以便在学习过程中不断地改进其策略。
相对于其他深度学习方法,强化学习的优势在于它可以处理更加复杂的问题。例如,在图像处理领域,深度学习可以用于分类、识别和分割等任务,而强化学习可以用于在复杂的环境中进行决策。此外,强化学习在处理无监督学习和半监督学习问题方面也具有优势。
Ilya如此强调强化学习,因为强化学习可能会是通往通用人工智能的一个关键步骤。由于强化学习可以通过与外界进行交互来获得经验,并根据经验改进自己的决策,因此它可以使智能体更具有适应性和灵活性,从而更接近于真正的人工智能。
上期,我们不是说过一直在玩强化学习的DeepMind吗?DeepMind是举着强化学习的一杆大旗。说实话,AlphaGo带给它的光环太大,也给他做事带来一些负担,就是老想在游戏场景里面去拿第一名。而OpenAI更专注于在强化学习的基础能力提升上蓄积力量:
- 优化算法的研究:在深度学习和强化学习中,优化算法的选择和设计可以显著影响算法的训练效率和收敛性能。因此,OpenAI致力于研究更加高效和鲁棒的优化算法,例如针对大规模分布式环境下的优化问题进行优化。
- 解释性和可靠性研究:在实际应用中,深度学习和强化学习算法往往被视为“黑盒子”,其内部运行机制难以解释和理解,同时也存在模型不稳定、样本不均衡等问题。为此,OpenAI研究如何提高模型的可解释性和可靠性,包括模型压缩、模型剪枝、自适应学习等技术。
- 自适应和泛化能力研究:在现实世界中,深度学习和强化学习算法需要具有一定的自适应和泛化能力,即能够适应不同的环境和任务,同时也能够处理噪声、异常数据等情况。因此,OpenAI致力于研究如何提高深度学习和强化学习算法的自适应和泛化能力,包括对抗性训练、数据增强、多任务学习等技术。
而且OpenAI并没有完全依靠自己的力量,而充分发挥了其非营利机构的光环,通过众包的方式调动尽可能的人工标注着(human annotator)来使用监督学习的方式来搞强化学习。这就是基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)名字的由来。
OpenAI有很强的社区和网络,这是他们能够找到并联系到大量专家的关键。他们与全球各地的大学、研究机构、工业界合作,拥有广泛的人脉和联系。此外,OpenAI还与许多国际会议、研讨会和竞赛合作,吸引了众多研究人员和工程师参与到他们的项目中来。这些活动可以为OpenAI提供一个平台,使他们能够与各种领域的专家建立联系,并且获得更多的资源和支持。同时,OpenAI还积极地招募和培养年轻的研究人员和工程师,通过他们的努力和才能来推动RLHF等研究的进展。这些都是OpenAI能够吸引和组织大量专家帮助完成RLHF的关键因素。
相比于其他强化学习方法,RLHF具有以下几个特点:
- 更高效的学习:在传统的强化学习中,智能体通过与环境的交互来学习,通常需要很多轮的尝试和错误才能找到最优策略。而在RLHF中,人类专家可以提供即时的反馈,帮助智能体更快地找到最优策略。
- 更高的安全性:由于人类专家可以对智能体的行为进行实时监控和干预,所以RLHF可以更好地保证系统的安全性。例如,在某些需要特殊处理的情况下,人类专家可以提供额外的指令或约束条件,以确保智能体不会做出危险或有害的决策。
- 更好的可解释性:由于人类专家可以提供详细的反馈和解释,RLHF可以更好地解释智能体的决策过程,使得人类能够更好地理解和信任智能体的行为。
需要注意的是,RLHF也存在一些限制和挑战。例如,人类专家需要花费大量的时间和精力来提供反馈,且人类反馈也可能存在偏见和不一致性。另外,RLHF也需要解决如何在人类反馈和自主学习之间进行平衡的问题。
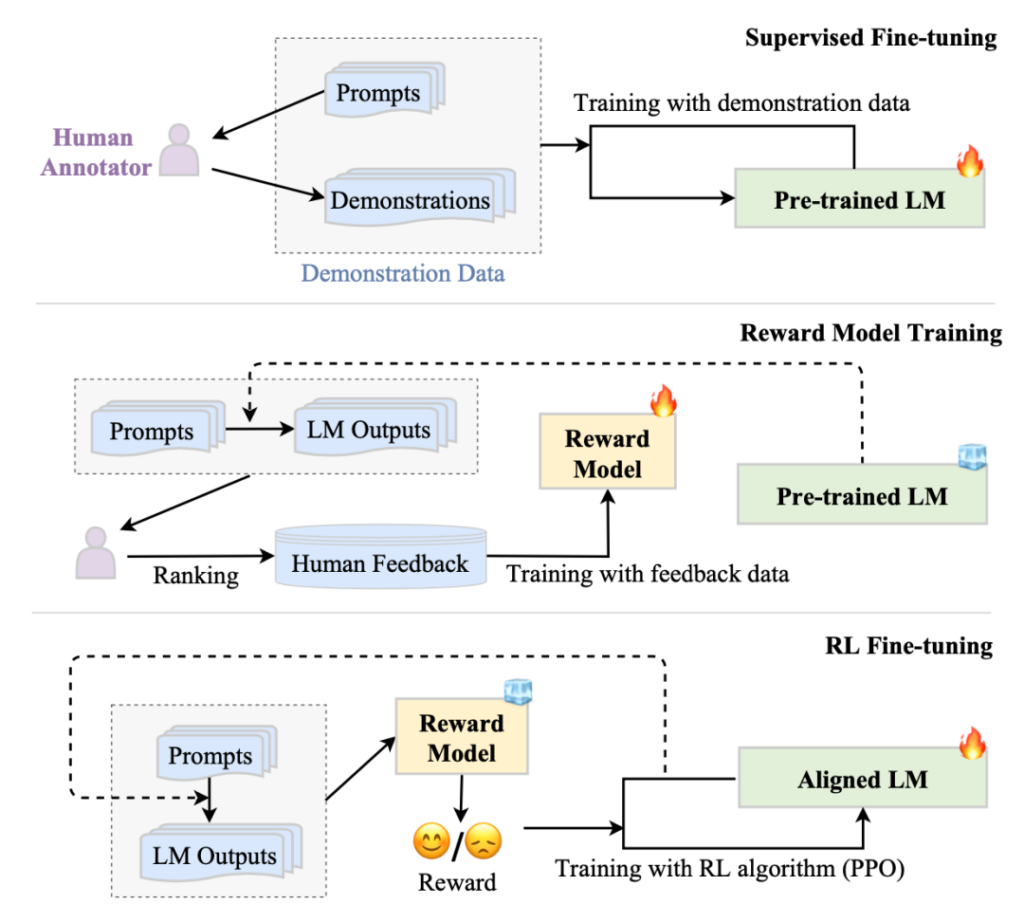
上图显示了RLHF进行对齐调整的过程,具体包含三个步骤:
第一步是基于人类标注数据做有监督精调。这一步和指令调整差不多,不过用的数据都是人类标注的,内容也更自由一些,比如开放式问答,闲聊,头脑风暴,改写等。这一步并非必须,可以认为是针对强化学习的冷启动问题的预热。
第二步是基于人类反馈训练一个奖励模型(Reward Model)。比如InstructGPT中基于标注数据训练了一个排序模型。奖励模型将在第三部强化学习中提供反馈信号。奖励模型一般是一个较小的大语言模型,例如;GopherCite基于2800亿参数的Gopher做调整,奖励模型采用70亿的Gopher。
第三步是强化学习优化的过程。待优化的大语言模型的动作域(action space)是预测词表,状态为当前生成的内容,并将奖励模型的反馈信号通过PPO算法传给大语言模型做优化。对了避免强化学习跑偏,RLHF还采用了优化后的模型与原模型生成内容的KL距离作为正则项。
所以我理解为什么OpenAI能成功,大概率和有监督学习,以及人工的介入有关。而且这不是少数人介入,而是海量的人力投入。这个听起来没有无监督学习和强化学习那么高大上,所以反复被Ilya轻描淡写地说,这也许不重要(事实可能很重要),似乎也是OpenAI不愿意对外多披露的原因。
游戏功臣DOTA
如果你要问打游戏有什么用的话,别忘了AlphaGo。当时AlphaGo打败人类那是掀起了多大的波浪。打游戏是强化学习训练最好的手段。DeepMind能搞AlphaGo(围棋)和AlphaStar(星际争霸),OpenAI也可以玩其他的游戏。当然,OpenAI可能醉翁之意不在酒,他还真不是为了打游戏求出名,而是为了调优强化学习的算法能力本身。真可谓看山不是山。
DOTA 2是一个多人在线战斗竞技游戏,每个玩家扮演一个英雄角色,与其他玩家的角色对战,通过不断地升级、购买装备等方式来获得胜利。DOTA 2是一款非常复杂的游戏,涉及到大量的策略、决策和技能,因此非常适合用来进行强化学习的研究和实验。
OpenAI在2017年到2019年间,多次举办了Dota2 AI与职业选手的对局,当时被冠以“人机大战”的噱头, 研究游戏看似是他们走的一条弯路,但也在给OpenAI打响名声的同时,增强了团队对AI训练模型的理解,通过这些实验,OpenAI得以研究和开发了一些先进的强化学习技术,这些技术后来被用于训练ChatGPT。所以老黄才会在谈话中说,这个看似在走弯路,但现在回顾却发现正是这些弯路变相推动了ChatGPT的诞生。
在2017年的《DOTA2》国际邀请赛(TI7)上,OpenAI首次与《DOTA2》玩家见面。当时的OpenAI还无法进行5V5对战,只可进行中路单挑。在表演赛环节,主办方请来了TI1冠军队选手Dendi,他使用英雄影魔与OpenAI进行中路单挑。OpenAI展现了熟练的卡兵技巧,随后仅用4分40秒就2:0击败了Dendi。比赛期间,OpenAI官方在YouTube上发布视频,解释了为何团队选择用《DOTA2》来训练AI——《DOTA2》机制较为复杂且竞技性较强,AI在游玩中需要不断学习新的技能、新的玩法,才能达到和职业玩家相当的水平,这使《DOTA2》成为了很好的AI自我训练道具。
在此之后,OpenAI研发出了《DOTA2》5V5对战AI——OpenAI Five。5V5对AI之间的合作、策略规划提出了更高要求。在实际对战中,OpenAI Five的合作表现确实不如职业选手——2018年8月TI8,职业战队paiN在表演赛上对战OpenAI Five,最终取胜;在TI8的第二场表演赛上,BurNing徐志雷、骆非池iG_430等5位国内前职业选手组成小队,对战OpenAI Five,也同样取胜。
OpenAI Five在2018年的战绩并不好看,但它的成长速度超出了许多玩家的想象——2019年4月,OpenAI Five与TI8冠军战队OG进行BO3对战,官方对这次比赛进行了直播。
最终OpenAI Five以2:0的比分拿下了BO3胜利。期间还多次表演了诱敌深入、丝血逃命的“骚操作”。
比赛之后,OpenAI官方宣布在2019年4月18-21日举办Open Five擂台赛,期间全球玩家可自行组队挑战OpenAI Five。根据官方最终在推特上公布的数据来看,OpenAI赢得了7215场比赛,输掉了42场,胜率高达99.4%。没有必要追求绝对的第一,因为训练算法是目的,只要强化学习算法被调教好了,用在其他领域同样是利剑。
可能你会好奇,同样是玩游戏,为啥OpenAI的Open Five搞成了,而DeepMind的AlphaStar表现欠佳?
虽然 DeepMind 的 AlphaStar 和 OpenAI 的 Dota 2 AI 都是使用强化学习算法来打游戏,但是两者的实现方式和目标设置是不同的,导致 AlphaStar 在星际争霸游戏中的表现可能不如 OpenAI 的 Dota 2 AI。
首先,星际争霸是一款实时战略游戏,而 Dota 2 是一款团队对战游戏。从处理时间上看,这意味着在星际争霸中,玩家需要同时管理多个单位、制定战术、探测敌人并做出反应等等,这需要AI玩家在非常短的时间内处理更多的信息做出决策。而在 Dota 2 中,AI玩家的决策可以更加缓慢,因为他们有更多的时间来思考和协调策略。说白了,就是多人类配合,会降低整个人类团队的响应速度,但是AI团队不会,这就会给AI处理团队反映争取时间。因此从这个维度看,AlphaStar 比 Dota 2 AI 面临更大的挑战。
其次,AlphaStar 的目标是在星际争霸游戏中击败人类玩家,而 Dota 2 AI 的目标是在游戏中击败其他 AI 团队。这意味着 AlphaStar 必须学会适应各种人类玩家的策略和战术,而 Dota 2 AI 只需要学习如何击败其他 AI 团队的策略。从肇事打法的数量级来看,或许一个人的想法有千千万,但到了团队配合,反而招式受限了。毕竟人与人的沟通是有信息流失的,所以协作策略的沟通转化为实际团队行动,需要更多的沟通成本,在有限时间里反而都采用简化的协作策略?而且人类的合作,不得不说,很多时候还会有误判的。但是AI恰恰相反,AI之间可是全透明,无沟通障碍,无死角地协调,所以从这个维度上来看,OpenAI的Dota 2 AI团队似乎占了便宜。
此外,AlphaStar 的训练数据也可能比 Dota 2 AI 更加有限。虽然两个项目都使用了大量的游戏数据来训练 AI,但是或许星际争霸游戏的复杂性和难度可能使得 AlphaStar 需要更多的数据才能学会更好的策略。当然,也可能不仅仅是训练的问题,也许是算法问题,但是没有人直接比较两个算法的差异性,毕竟,都没有开源。所以,我也无法胡乱继续猜测下去,权且认为,也许这里面的原因非常复杂,不能简单定论吧。
躲在背后的另外一个游戏AI Dungeon
DOTA是站在聚光灯下的游戏,但还有一个游戏平台AI Dungeon,也是推进ChatGPT的另外一个幕后功臣,甚至可能作用更甚。
根据OpenAI官方的描述,他们使用了一个名为”AI Dungeon”的游戏平台,让玩家参与其中并提供反馈。这个平台使用了RLHF等技术,玩家可以通过与虚拟角色的互动来玩游戏,同时提供反馈以帮助AI改进。OpenAI并没有透露具体的人力资源量级,但他们强调AI Dungeon的用户数量已经超过了百万,这个数量级可以提供大量的反馈数据和资源。此外,OpenAI还与一些专业的游戏测试人员和AI专家合作,来进行更加深入的调优和测试。

尼克·沃尔顿(Nick Walton) 是 “AIDungeon” 的创始人和首席执行官。他在创立 AI Dungeon 前曾在微软和Google等科技公司工作,致力于开发人工智能和自然语言处理技术。他的目标是创建一个完全由人工智能驱动的游戏,可以提供无限的可能性和沉浸感,从而推动人工智能的发展和应用。叙事游戏AI Dungeon借助人工智能讲述无穷无尽、千变万化的故事。
故事可以追溯到2018年,当时Nick Walton正在开发一款名为”AI Dungeon”的文字冒险游戏。熟悉BBS的同学应该知道这种类型文字冒险游戏是什么体验。还真没有意识到,现在很多年轻也喜欢玩这类游戏。记得20多年前(暴露智愿君年龄了),当初我的很多同学,也是为了玩这种类型的游戏,在教研室熬通宵,课题论文都放下了。
不同于传统的文字冒险游戏,毕竟Nick是玩人工智能的,所以Nick觉得,传统的基于规则的游戏设计方法很难创建真正的互动体验,因此他开始尝试使用AI来生成游戏中的内容。
在寻找适合的AI技术时,他发现OpenAI的GPT-2模型能够以惊人的方式生成自然语言文本,包括故事、角色和世界设置。他使用GPT-2模型来生成游戏中的文字内容,并发现这种方法产生了惊人的效果,使得游戏更加生动和丰富。
Nick Walton向OpenAI展示了他的工作成果,引起了OpenAI的兴趣。OpenAI认为这种使用AI生成游戏内容的方法非常有趣和有潜力,因此他们与Nick Walton开始了合作。他们将GPT-2模型嵌入到AI Dungeon中,创造了一个可以无限扩展、完全个性化的游戏世界。
游戏反响非常好。很快就登上了黑客新闻的榜首。有了GPT的加持,一周之内,AI Dungeon就有了超过 10 万名玩家,其中超过一半玩家从头到尾完成了游戏。随着用户量的上升,成本随之而来。两周内,服务器的数量就达到了715台的峰值,六周后,迎来了100万用户,创造了600万个独特的故事。
AI Dungeon 的玩家群体非常广泛,因为它提供了一个高度自由、无限可能性的游戏世界,玩家可以在游戏中发挥自己的想象力,创造出独一无二的故事情节和角色。因此,对于喜欢创作、喜欢探索奇幻世界、喜欢挑战自己想象力的人来说,AI Dungeon 是一个非常有吸引力的游戏。此外,AI Dungeon 的技术也吸引了许多对人工智能和机器学习感兴趣的人,他们可以通过AI Dungeon了解和探索相关技术的应用和实现。
Nick曾说:“我绝对相信 AI 将在未来五年内从根本上改变游戏业。AI 开辟了无限可能性:逼真的角色扮演,为玩家提供更大的行动自由,以及生动活泼的游戏世界。”他说对了,也不全对,因为当时他没有意识到,他使用的GPT不仅仅从根本上改变了游戏,而且改变了整个世界。
好了,今天我们先解读到这里。下次,我们会继续针对黄仁勋与Ilya Sutskever的“炉边谈话”的其他部分进行解读,敬请期待。