河套 IT TALK——TALK 42:(原创)视频制作的人工智能时代要到来了,你准备好了吗?
一幅获奖的画在艺术界炸了锅
近几个月,关于图像生成(Text To Image)的人工智能艺术创作,成为科技媒体的热点话题。从DALL-E,到Stable Diffusion,再到Midjourney,我们能明显看到深度学习在图像生成方面肉眼可见的巨大进步。这些人工智能艺术创作工具在艺术界更是引发了不少插画设计师和艺术家的职业焦虑。特别是去年9月份,当杰森·艾伦 (Jason Allen) 将他的“空间歌剧院”提交给科罗拉多州博览会的美术比赛时,这幅华丽的印刷品立即大受欢迎,作品中多个人物的肖像,飘逸的长袍,凝视着明亮的远方,复古风和星际风混搭的如此完美,且精细,立即征服了评委。在“数字处理摄影”类别中击败了其他 20 位艺术家,赢得了第一名蓝色丝带和 300 美元的奖金。

然后,艾伦告诉大家,这件艺术品是由人工智能工具Midjourney 创作的。这无疑在艺术界炸开了锅。很多艺术家开始谴责艾伦用欺骗的手段获得了奖项。甚至上纲上线,认为Midjourney这类Text to Image的生成工具,将彻底破坏人们的创造性,模糊艺术的边界,甚至扼杀人类的艺术本身。
但吵归吵,事情已经发生,而且还有愈演愈烈的趋势。最近,几个文本到视频(Text to Video)的工具悄然兴起,让生成对抗网络( GAN ) 和扩散模型的机器学习技术突破了图片生成的边界,延展到了视频生成领域。今天我们会介绍三款近期刚刚萌芽的文本到视频的生成工具。这些工具或许当下看起来都还非常青涩,但也足够惊艳。根据文本到图像的发展速度,相信今年,最迟明年,这种技术就会成熟到炉火纯青的程度,不信等着瞧:)
Gen-1
就在近期,Runway推出了一款新的文本到视频的工具Gen-1。使用文字和图像从现有视频中生成新的视频。效果请先看视频:
这个工具有五种使用模式:
风格化(Stylization):将任何图像或提示的风格转移到视频的每一帧。
故事板(Storyboard):将模型变成完全风格化和动画的渲染。
遮罩(Mask):隔离视频中的主题并使用简单的文本提示对其进行修改。
渲染(Render):通过应用输入图像或提示,将无纹理渲染变成逼真的输出。
定制(Customization):通过自定义模型以获得更高保真度的结果,释放 Gen-1 的全部功能。

Runway到底是何方神圣?在Runway的主页上,我们看到他们的slogan是:“Everything you need to make anything you want.”(这里有你制作任何东西所需的一切)。“Make the impossible & Move Creativity Forward” (创造可能,推进创意)。他们的网站上,你能找到几十种AI多媒体(图像、声音、视频动画)处理的小工具。Gen-1只是其诸多工具中的一个。
如果大家熟悉Stable Diffusion的话,就会明白,Stable Diffusion是由多家联合发布的。Runway就是其中之一。
Stable Diffusion是一种潜在的扩散模型(LDM),深度生成神经网络,代码和模型权重已经开源,对外发布。Stable Diffusion 由 3 部分组成:变分自动编码器(VAE)、U-Net和可选的文本编码器。Stable Diffusion数据训练采用的是Common Crawl数据,其中包括 50 亿个图像-文本对。
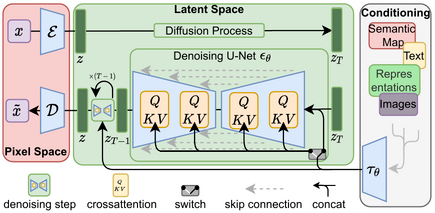
这次Runway发布的Gen-1,用到的还是Stable Diffusion的能力。
Runway是在2018年,由几位在纽约大学Tisch艺术学院交互式电信项目(ITP)的研究员:克里斯托弗·巴伦苏埃拉(Cristóbal Valenzuela)、亚历杭德罗·马塔马拉(Alejandro Matamala )和阿纳斯塔西斯·泽玛尼迪斯(Anastasis Germanidis)成立的创业公司。
他们几位痴迷于艺术与技术交集给艺术创作带来的帮助。几位年轻人坚信:利用计算机图形学和机器学习的最新进展来突破创造力的极限,进而降低内容创作的障碍,必然会开启新一波讲故事的浪潮。
Google Dreamix
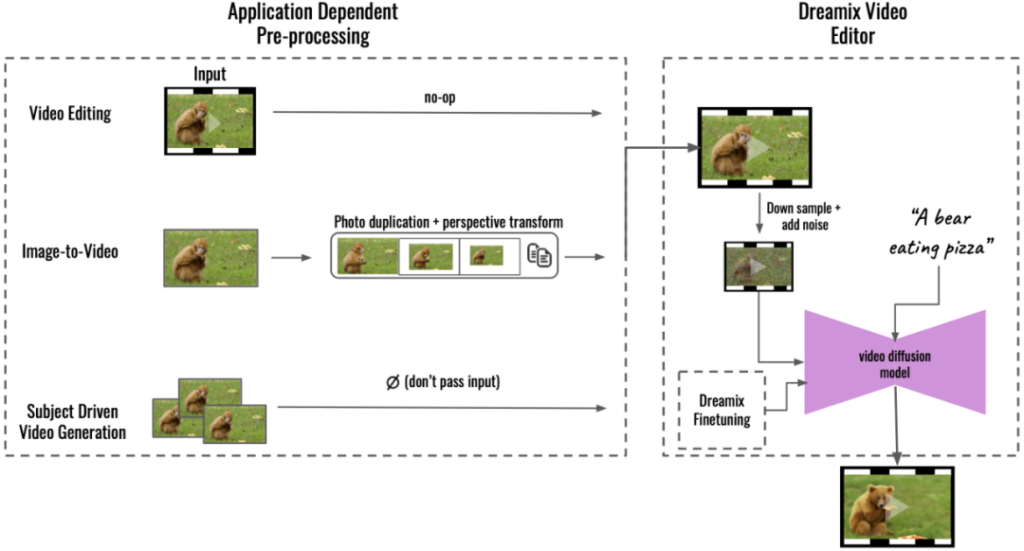
就人工智能的龙头老大而言,我们不得不佩服Google。近期,Google也发布了一款Text to Video通用视频编译器Google Dreamix。这款工具提供三种工具模式:
1. 对已有视频的编辑:提供一个输入视频,再给出一段文字描述,并根据这段文字描述对图像进行修订。
2. 提供一张图片,再对这张图片提供一段描述,然后生成一段视频来来让这个图片动起来。
3. 提供一系列图片,然后再提供一段描述,根据输入图片的素材,产生一个视频动画符合描述的含义。
从技术上来说,对于视频编辑,Dreamix 将源图像加噪并将它们传递给视频扩散模型,然后该模型根据文本提示从噪声源图像生成新图像并将它们组合成视频。因此,源图像提供了一种草图,可以捕捉例如动物的形状或其运动,同时留出足够的变化空间。

Google在人工智能贡献远远不是Dreamix这么简单。这个世纪以来至少有几件事儿,Google是功不可没的:
- 2011年,谷歌人工智能研究部门Google AI和斯坦福大学教授吴恩达合作,成立了一个深度学习的团队,取名非常大胆,叫:谷歌大脑(Google Brain),杰夫·迪恩(Jeff” Dean)是负责人。目的是将开放式机器学习研究与信息系统和大规模计算资源相结合。2015年,谷歌大脑搞出来一个TensorFlow。这是一个在Apache License 2.0下开源的用于机器学习和人工智能的免费开源软件库。采用于深度神经网络的训练和推理。后续很多机器学习的初创公司都受益于TensorFlow。
- 针对TensorFlow,Google开发了新的硬件Tensor Processing Unit(TPU),这是一种专门为神经网络机器学习开发的AI加速器专用集成电路(ASIC)。谷歌于 2015 年开始在内部使用 TPU,并于 2018 年将其提供给第三方使用,既作为其云基础设施的一部分,也通过出售较小版本的芯片。TPU对待深度卷积神经网络的运算效率要高于GPU。当然我们要承认,由于TPU仅仅是为了TensorFlow的优化,目前主流的人工智能图像生成领域,硬件还是以GPU为主。2007年,随着 Nvidia GeForce 8 系列的推出,以及随后新的通用流处理单元,GPU 成为一种更通用的计算设备。GPU 上的通用计算开始真正进入机器学习领域,让标准神经网络在GPU实施比CPU上的等效实施快 20 倍。正是因为这种边际成本的变化,才激发了很多初创公司开始投身于人工智能的领域。
- Google工程师 亚历山大·莫德文采夫(Alexander Mordvintsev )为2014年ImageNet大规模视觉识别挑战赛(ILSVRC)开发了一个深度卷积计算机视觉程序DeepDream。这名字来源于电影《盗梦空间》。DeepDream使用卷积神经网络通过算法错视来查找和增强图像中的模式,从而在故意过度处理的图像中创造出一种梦幻般的外观,让人联想到迷幻体验。2015年7月,程序发布后,被行业热捧,也激发了很多艺术界的人士,意识到用机器学习充实艺术创作的巨大潜能。
- 2017年,Google Brain团队又搞出来一个深度学习模型Transformer,采用自注意力机制,对输入数据的每一部分的重要性进行差异加权。这个模型直接刺激了预训练系统的发展。Transformer在自然语言处理和图像处理都表现了非凡的优势。后来的OpenAI的GPT,就是基于Transformer的应用。
当然,除了Google之外,另外一家行业大佬Meta也没有闲着。尽管操作了很久的元宇宙并未达到预期效果,Meta还是在图像生成领域做了大胆的尝试。
Make-a-Video
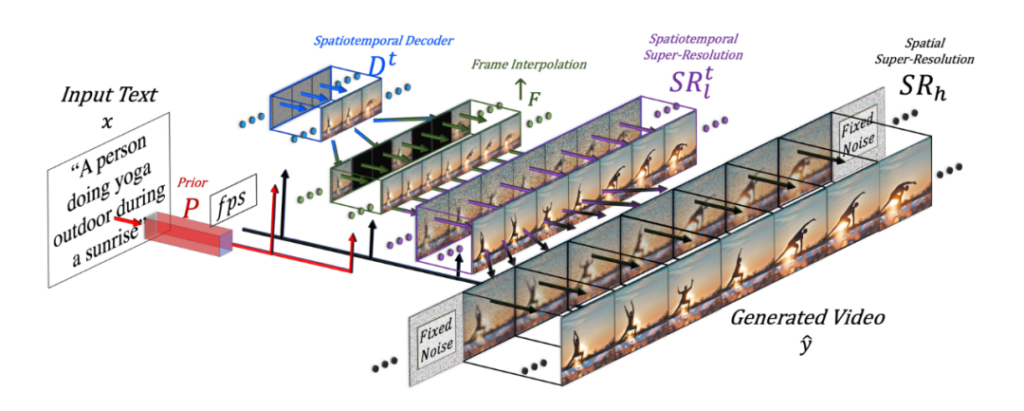
Meta AI是Meta平台公司(原Facebook)的人工智能实验室(FAIR)。最近Meta AI搞了一个工具,叫Make-a-Video。是一款通过深度学习的方式实现从文本到视频。Make-a-Video支持三种用法:
1. 单纯的Text to Video,人们可以使用尽可能详尽的语言来描绘视频的内容,以及选定对应视频的风格(现实、超现实主义、风格化),然后来生成对应的视频,比如:
泰迪熊在画自画像

2. 从静到动(From Static to Magic)
比如一艘大海航行船的图像:

可以通过Make-a-Video生成一个动图:

3. 为视频添加额外的创意
可以根据原始视频创建视频的变体,比如下面这个多色的毛茸跳舞者

通过Make-a-Video可以生成多个变体:


从技术上来看,Meta这个工具首先可以分解完整的时间U-Net和注意力张量,并在空间和时间上进行近似。其次,设计了一个通过差值模型来实现时空管道来生成高分辨率和帧率的视频。
几年前的Image to Image
其实人工智能在艺术领域的介入从2015年左右就开始进入大众的视野了。那个时候,主要的应用场景是通过神经网络和人工智能应用某些艺术效果来转换已有的图片。相信大家都有印象包括Prisma、Pikazo、Painnt、Lucid、Artisto、Style和DeepArt等一系列的App出现在应用市场上。这些App多半是将人工智能作为特效滤镜的方式来运用,把一张普通的照片,转换为梵高、莫奈、达利和毕加索等等一系列艺术画风格的作品,当然,高级一些的,还会生成视频。

之所以卡在这个时间点突然出现,主要要归功于伊恩·古德费洛(Ian Goodfellow)完成了一项人工智能神经网络的研究,发明了生成对抗网络(Generative adversarial network,简称GAN)。这种技术可以让经过照片训练的 GAN 可以生成新照片,这些照片至少在人类观察者看来是真实的,具有许多现实特征。最初GAN是作为无监督学习的生成模型形式提出来的,但事实证明,GAN也可以用于半监督学习、全监督学习、和强化学习。

随着伊恩·古德费洛毕业加入Google后,他的同事就用他的GAN搞了一个DeepDream,这种奇幻的效果立即给AI艺术创作届打了一针强心剂。紧接着,一堆的初创公司就如春笋般生长起来了。
开源在技术上迸发的力量
软件开源,尽管现在已经几乎众人皆知的开发模式,但其实从前麻省理工学院人工智能实验室的研究员理查德·斯托曼(Richard Stallman)不满闭源软件的不便,进而在Dr. Dobb‘s软件杂志上愤然发表《GNU宣言》(The GNU Manifesto),直到2005年,30年过去了,从自由软件到开源,还一直都是小圈子的事情。

2005年,莱纳斯·托沃兹(Linus Torvalds)开发了Git,进而在2007年孵化出GitHub,才彻底改变了局面。GitHub的出现,让开源项目全球化协作和软件版本管理变得无比便捷。
而正是因为用于机器学习和人工智能的免费开源软件库TensorFlow、OpenAI的GPT模型代码和GPT-2和Google深度学习模型Transformer等等这些软件能力被开源了,才会被世界上其他心中有艺术梦想的程序员所获得,才会激发这个图像生成产业的繁荣。
也正是这个原因,当看到OpenAI不再把自回归语言模型GPT-3继续开源之后,我心中开始对这家公司表示质疑,估计OpenAI会在短期盈利,但是很难走的长远。
优质的数据训练是基础

2001年,美国法律学者和政治活动家、哈佛大学教授劳伦斯·莱西格(Lester Lawrence Lessig)拉着哈罗德·阿贝尔森和埃里克·埃尔德雷德在红帽罗伯特·扬(Bob Young)的公共领域中心支持下,成立了一个非营利组织知识共享组织(Creative Commons ,简称CC ) 。鼓励创作者采用“CC授权”,来推动知识和作品的共享和创新,积极促成学术资料、音乐、文学、电影和科学作品对大众开放, 并向全球各国推广。

同年,由吉米·威尔士(Jimmy Wales)发起的多语言的免费在线百科全书维基百科启动。内容许可遵守CC Attribution 和 Share-Alike 3.0。

2012年,亚马逊Amazon Web Services开始通过Common Crawl基金会这个非营利组织负责抓取网络并免费向公众提供其档案和数据集。致力于使互联网信息访问民主化的非营利组织。
没有这些符合CC协议的优质内容的大型平台,GAN的机器学习,算法再好,也是无源之水。比如:也正是有了CC协议的这些优质数据资源,类似LAION(德国的非营利组织)才能够去调用这些数据,专门训练很多备受瞩目的文本到图像模型,包括Stable Diffusion和Imagen。
不可阻挡的艺术平民化
艺术圈的很多人都明白,艺术在当代社会的生存空间已经被极大地压缩了。圈内人流传一种说法:艺术家不会忙死,不会焦虑死,但艺术家会被饿死。现在很多艺术创作工具都是商业化工具,购买软件要花费高昂的成本,对于很多刚刚踏足艺术工作的新人来讲,这些预支成本往往带来巨大的生存压力。
从最近图像生成、视频生成炒作热度可以看出,艺术界的这种诉求非常强烈。今天介绍的几个工具,应该都是深知艺术圈这种窘境和痛苦的。他们的使命就是让所有人都能零起步低成本创作内容。他们也明白,解决这个问题的关键在于要拥抱机器学习的AI时代,他们坚信机器学习能让艺术创作民主化,平等化,而不是被垄断在大的广告公司和特效公司手里。
艺术平民化的道路,其实从文艺复兴后,一直都在不停地迭代,从印象派到抽象派到达达主义之后到波普艺术,都是在简化艺术创作的难度和门槛上变得越来越容易,而AI让这个进程又加速了,让普通人不仅仅可以创作艺术,而且还能创作出艺术家才能创造的高品质的艺术作品,这无疑是一种变革。因为AI让普通人站在了艺术界巨人的肩膀上。
写在最后
我们经常会为一个新的技术热点出现而兴奋,但每个热点的背后,都不是凭空产生的。在到达引爆媒体的临界点之前的蓄能阶段,有很多的技术和平台,都在孵化这个引爆点。如果用放大镜去看,都有有轨迹可循的。我们会洞见到:生态界和教育界的配合,非营利机构和营利产业界的配合,某些行业领袖开放开源的胸怀。而往往每一环都是关键的助推力量,缺少任何一环,技术的引爆点都可能会延迟数年,甚至数十年。但有一点是明确的:是金子,最后一定会发光,但天时地利人和是何时何地发光的关键。