《老子到此一游系列》之 老子带你看懂这些风景—— 多维探秘通用无损压缩 第四章 Lempel-Ziv Parsing(转发)

ELT.ZIP是谁?
ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
成员:
上海工程技术大学大二在校生 闫旭
合肥师范学院大二在校生 楚一凡
清华大学大二在校生 赵宏博
成都信息工程大学大一在校生 高云帆
黑龙江大学大一在校生 高鸿萱
山东大学大三在校生 张智腾

ELT.ZIP是来自6个地方的同学,在OpenHarmony成长计划啃论文俱乐部里,与来自华为、软通动力、润和软件、拓维信息、深开鸿等公司的高手一起,学习、研究、切磋操作系统技术…
本文的梳理来自其中的四名同学:闫旭、楚一凡、赵宏博和高云帆。
前期回顾
《老子到此一游系列》之 老子带你看懂这些风景—— 多维探秘通用无损压缩 第一章 熵编码器/第二章 BWT算法
《老子到此一游系列》之 老子带你看懂这些风景—— 多维探秘通用无损压缩 第三章 基于BWT的改进算法
第四章 Lempel-Ziv Parsing
4.1 概述
Lempel-Ziv 算法由 Abraham Lempel 和 Jacob Ziv 在《A Universal Algorithm for Sequential Data Compression》最早引入。和 Burrows-Wheeler 算法一样,Lempel-Ziv的名称也是由其发明者命名。
Lempel-Ziv 算法有两个版本,根据发明日期分别为 1977年的LZ77 和 1978年的LZ78,其后又衍生出了不少像deflate,lzx,lzma这样优秀的变体算法。
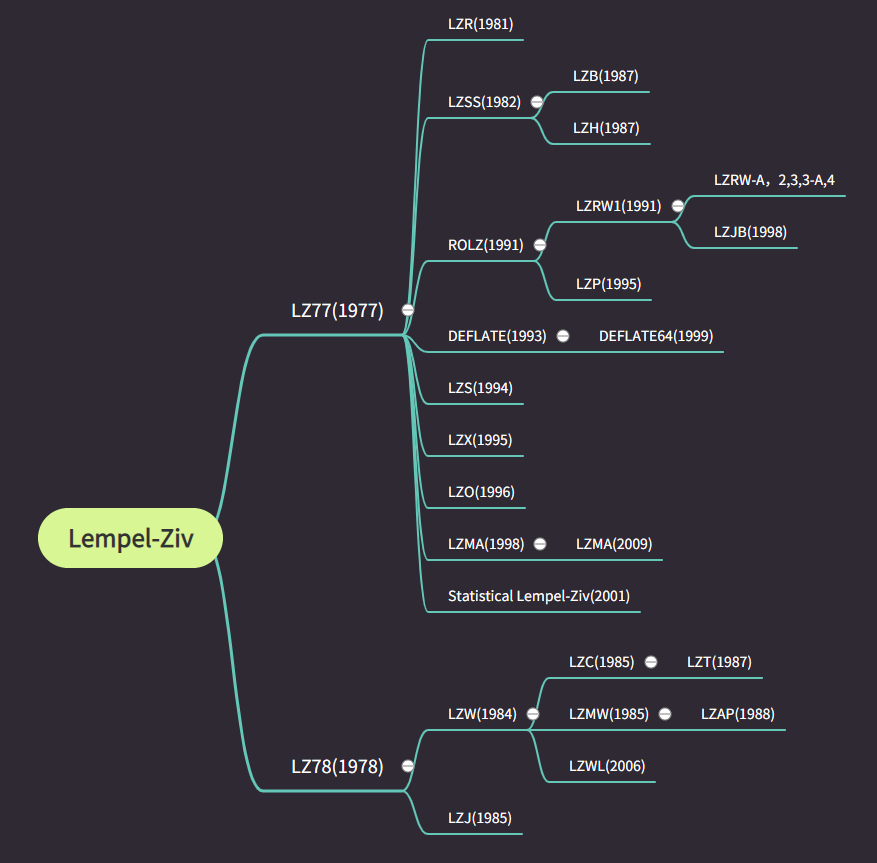
这里有一个比较有意思的事情,仔细看,会发现先发明出的LZ77算法的变体比LZ78多,是因为LZ77被人们使用的时间长吗?并不是,这是因为LZ78算法在1984年被Sperry申请了其变体lzw算法的专利,并开始起诉相关软件供应商等在没有许可证的情况下使用率GIF格式,之后LZ78算法的普及逐渐衰减。尽管LZW的专利问题已经平息,并出现了很多 LZW变体,但目前只有在 GIF压缩中被普遍使用,占据主导地位的仍是LZ77算法。
尽管 Lempel-Ziv算法有很多变体,但它们都有一个共同的思想:如果一些文本不是均匀随机的,也就是说,所有字母出现的可能性不一样,那么已经出现过的子串会比没有看过的子串更可能再次出现。举个例子:在我们日常生活中,我们都有一些日用语,比如“你好”,“你好吗”;那么,“你好”,“你好吗”,“你好吗”中包含字串“你好”,我们便可以把“你好”简化为更短的二进制码,来替换“你好吗”中的“你好”,从而简化编码。
4.1 LZ78
LZ78 算法通过构建出现在⽂本中的⼦字符串字典来⼯作。
算法有两种情况:
- 若当前字符未出现在字典中,则将该字符编码进字典
- 若当前字符出现在字典中,则从当前字符开始与字符做最长匹配,并将匹配到的最长子串后的第一个字符做特殊处理,并编码进字典。
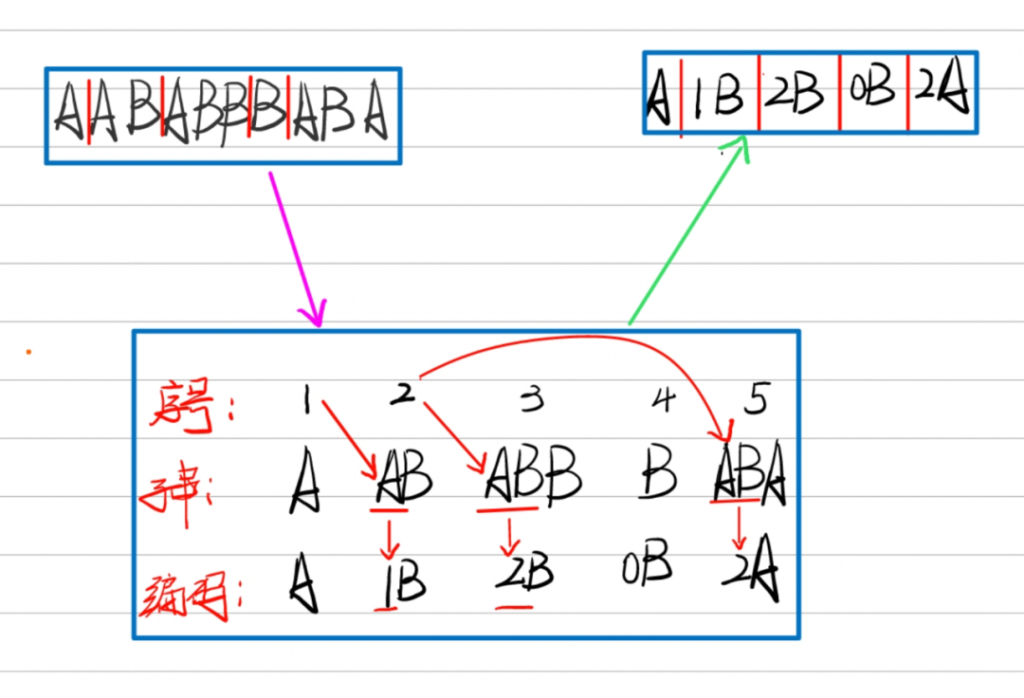
举例:假设我们有字符串 AABABBBABA ,我们使用 LZ78算法对其进行压缩。
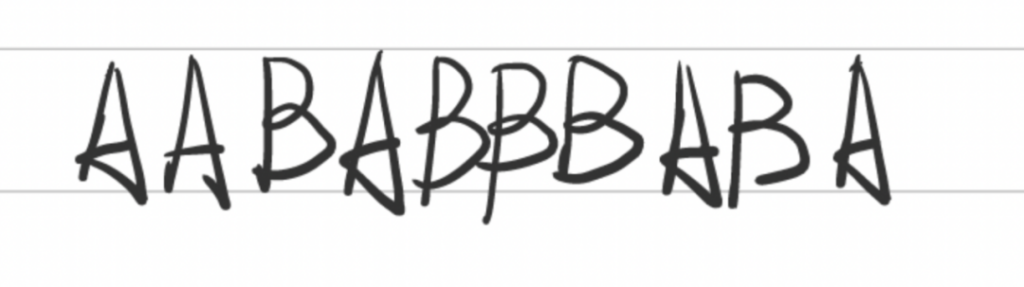
1. 先从左边最短并从未出现过的短语开始,这里是A,放入字典。
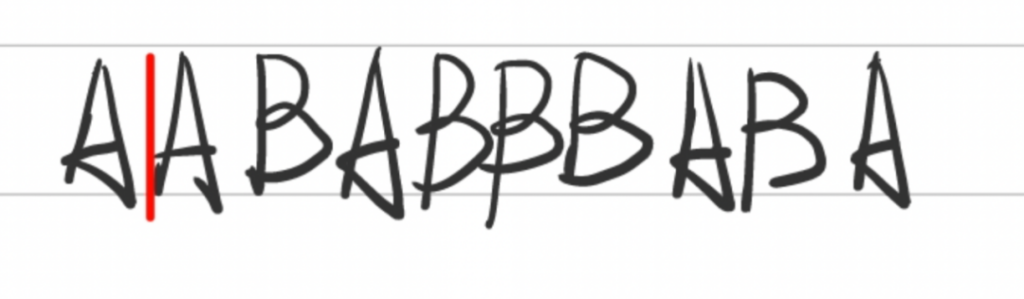
2. 接下来考虑剩下的字符串,由于之前已经见过A了,匹配最长字串A,并取最长字串的下一个字符做特殊处理,取AB放入字典。

3. 再考虑剩下的字符串,由于之前已经见过A了,继续匹配下一位B,此时最长字串为AB,继续匹配下一位,未匹配到最长字串,取ABB编入词典。

4. 考虑剩下的字符串,第一个字符是B,未匹配到最长字串,编入词典。

5. 同理,匹配剩下的字符,匹配到最长字串AB,连同下一位编入词典。
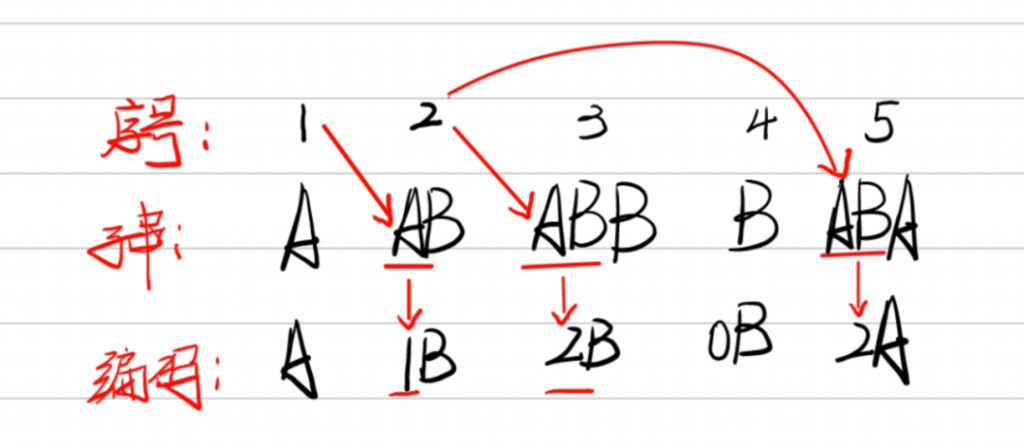
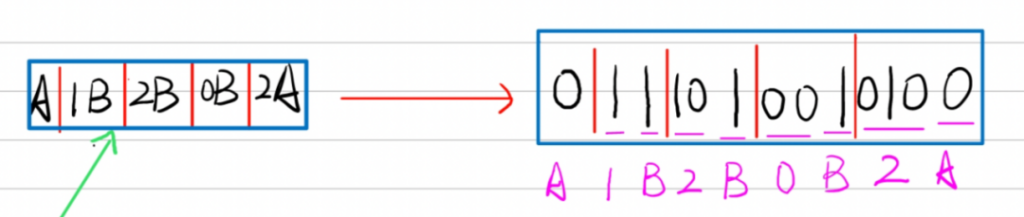
由于序号(index)2的字串AB中有A,可以用A的序号来替换字串A,编码AB为1B。同理,序号(index)3的字串ABB中有最长字串AB,可以用AB的序号替换ABB中的AB,编码为2B。序号(index)4的字串B与前面的字串没有匹配,为空集Ø,编码为0B。序号(index)5的ABA编码为2A。
此时,我们就用字典将原来的字串编码成了一个更简单的串,简化了相关变量,此时我们只需要给A和B赋值即可得到最终编码的二进制串。这里假设A=0,B=1。
LZ78 算法动态构建其字典,只遍历数据一次,这意味着不必在开始编码之前接收整个⽂档。
下期预告
第五章:双标准数据压缩
第六章:连续小波变换
第七章:OpenHarmony内核子系统之文件系统和压缩器
参考文献
[1] Deorowicz S . Universal Lossless Data Compression Algorithms[J]. Philosophy Dissertation Thesis, 2003.
https://www.researchgate.net/publication/2910531_Universal_Lossless_Data_Compression_Algorithms
[2] Burrows M , Wheeler D J . A Block-Sorting Lossless Data Compression Algorithm[J]. technical report digital src research report, 1995.
https://www.researchgate.net/publication/2702058_A_Block-Sorting_Lossless_Data_Compression_Algorithm
[3] Gao X , Dong M , Miao X , et al. EROFS: a compression-friendly readonly file system for resource-scarce devices. 2019.
https://dl.acm.org/doi/abs/10.5555/3358807.3358821
[4] Ni G . Research on BWT and Classical Compression Algorithms[J]. Computer & Digital Engineering, 2010.
http://en.cnki.com.cn/Article_en/CJFDTOTAL-JSSG201011009.htm
[5] Farruggia A , Ferragina P , Frangioni A , et al. Bicriteria data compression[J]. Society for Industrial and Applied Mathematics, 2013.
https://xueshu.baidu.com/usercenter/paper/show?paperid=27a6024fe31d2cda63a5e79b34be6cfd
[6] Alakuijala J , Farruggia A , Ferragina P , et al. Brotli: A General-Purpose Data Compressor[J]. ACM Transactions on Information Systems, 2018, 37(1):1-30.
[7] Overview – The Hitchhiker’s Guide to Compression (go-compression.github.io)
https://go-compression.github.io/
[8] Wavelet Tutorial – Part 1
https://users.rowan.edu/~polikar/WTpart1.html
[9] Wavlet Tutorial – Part 2
https://users.rowan.edu/~polikar/WTpart2.html
[10] Wavelet Tutorial – Part 3
https://users.rowan.edu/~polikar/WTpart3.html
缩略语列表
| 缩写 | 英文 | 中文 |
| ANS | Asymmetric numeral systems | 非对称数字系统 |
| BSLDCA | The Block Sorting Lossless Data Compression Algorithm | 块排序无损数据压缩算法 |
| BTW | Burrows–Wheeler Transform | Burrows–Wheeler转换 |
| BWCA | Burrows-Wheeler Compression Algorithm | Burrows-Wheeler压缩算法 |
| CTW | Context Tree Weighting | 上下文树加权 |
| CWT | Continue Wavelet Transform | 连续小波变换 |
| DMC | Dynamic Markov Coding | 动态马可夫压缩 |
| DWT | Discrete Wavelet Transform | 离散小波变换 |
| EC | Entropy Coder | 熵编码器 |
| MCO | Multi-Criteria Optimisation | 多标准优化 |
| MTF | Move To Front Transform | 前移变换 |
| PPM | Prediction by Partial Matching | 通过部分匹配进行预测 |
| RLE-0 | Zero Run Length Encoding | 零游程编码 |
| STFT | Short-time Fourier transform | 短时傅里叶变换 |
写在最后:
OpenHarmony 成长计划—“啃论文俱乐部”(以下简称“啃论文俱乐部”)是在 2022年 1 月 11 日的一次日常活动中诞生的。截至 3 月 31 日,啃论文俱乐部已有 87 名师生和企业导师参与,目前共有十二个技术方向并行探索,每个方向都有专业的技术老师带领同学们通过啃综述论文制定技术地图,按“降龙十八掌”的学习方法编排技术开发内容,并通过专业推广培养高校开发者成为软件技术学术级人才。
啃论文俱乐部的宗旨是希望同学们在开源活动中得到软件技术能力提升、得到技术写作能力提升、得到讲解技术能力提升。大学一年级新生〇门槛参与,已有俱乐部来自多所高校的大一同学写出高居榜首的技术文章。
如今,搜索“啃论文”,人们不禁想到、而且看到的都是我们——OpenHarmony 成长计划—“啃论文俱乐部”的产出。
OpenHarmony开源与开发者成长计划—“啃论文俱乐部”学习资料合集
1)入门资料:啃论文可以有怎样的体验
https://docs.qq.com/slide/DY0RXWElBTVlHaXhi?u=4e311e072cbf4f93968e09c44294987d
2)操作办法:怎么从啃论文到开源提交以及深度技术文章输出https://docs.qq.com/slide/DY05kbGtsYVFmcUhU
3)企业/学校/老师/学生为什么要参与 & 啃论文俱乐部的运营办法https://docs.qq.com/slide/DY2JkS2ZEb2FWckhq
4)往期啃论文俱乐部同学分享会精彩回顾:
同学分享会No1.成长计划啃论文分享会纪要(2022/02/18) https://docs.qq.com/doc/DY2RZZmVNU2hTQlFY
同学分享会No.2 成长计划啃论文分享会纪要(2022/03/11) https://docs.qq.com/doc/DUkJ5c2NRd2FRZkhF
同学们分享会No.3 成长计划啃论文分享会纪要(2022/03/25)
https://docs.qq.com/doc/DUm5pUEF3ck1VcG92?u=4e311e072cbf4f93968e09c44294987d
现在,你是不是也热血沸腾,摩拳擦掌地准备加入这个俱乐部呢?当然欢迎啦!啃论文俱乐部向任何对开源技术感兴趣的大学生开发者敞开大门。

后续,我们会在服务中心公众号陆续分享一些 OpenHarmony 开源与开发者成长计划—“啃论文俱乐部”学习心得体会和总结资料。记得呼朋引伴来看哦。
扫码添加 OpenHarmony 高校小助手,加入“啃论文俱乐部”微信群